Table of Content
- MetaFS Query & Aggregation Pipeline: Core & GUI
- MetaFS::Cloud on GPU via Docker
- MetaFS::Cloud & Semantics Extended
- Semantics Extended
- Partial Rewrite of the Core
- MetaFS Paper Published (Preview)
- IndexDB & Semantic Handlers
- Updating Web-Site
- Working on Stable
- MetaFS::IndexDB
- File Browser & Image Query Screencast
- General Query
- Image Query
- Changelog 0.4.9
- MongoDB vs Others
- Fully Indexed DB Tests
- Image (Color) Theme
- MetaFS Archive (marc)
- Changelog 0.4.7
Describing significant features and improvements of :
MetaFS Query & Aggregation Pipeline: Core & GUI
posted 2016/11/26 by rkmMongoDB Query and MongoDB Aggregation Pipeline compatible functionality has been implemented
- Query.pm & Aggregation.pm: for core and handlers, regardless whether MongoDB as backend is used, giving PostgreSQL or IndexDB extended Query & Aggregation functionality
- Query.js & Aggregation.js: for GUI, sub-querying and sub-aggregation for quick visualization
MetaFS::Cloud on GPU via Docker
posted 2016/09/09 by rkm
The semantic backend handlers of caption (NeuralTalk2) and densecap (DenseCap) are based complex setups (comprehensive dependencies), also imagetags (Darknet with ImageNet/Darknet model) running on
NVIDIA's GPU CUDA platform brings a speed up of 10-90x compared to CPU-only version, using nvidia-docker:
caption: 200-300ms per evaluation (CPU 1.5-2 secs, 10x)densecap: 500-600ms per evaluation (CPU 16-24 secs, 30x)imagetags: 3-4ms per evaluation (CPU 0.2-0.3 secs, 90x)
MetaFS::Cloud & Semantics Extended
posted 2016/05/01 by rkm
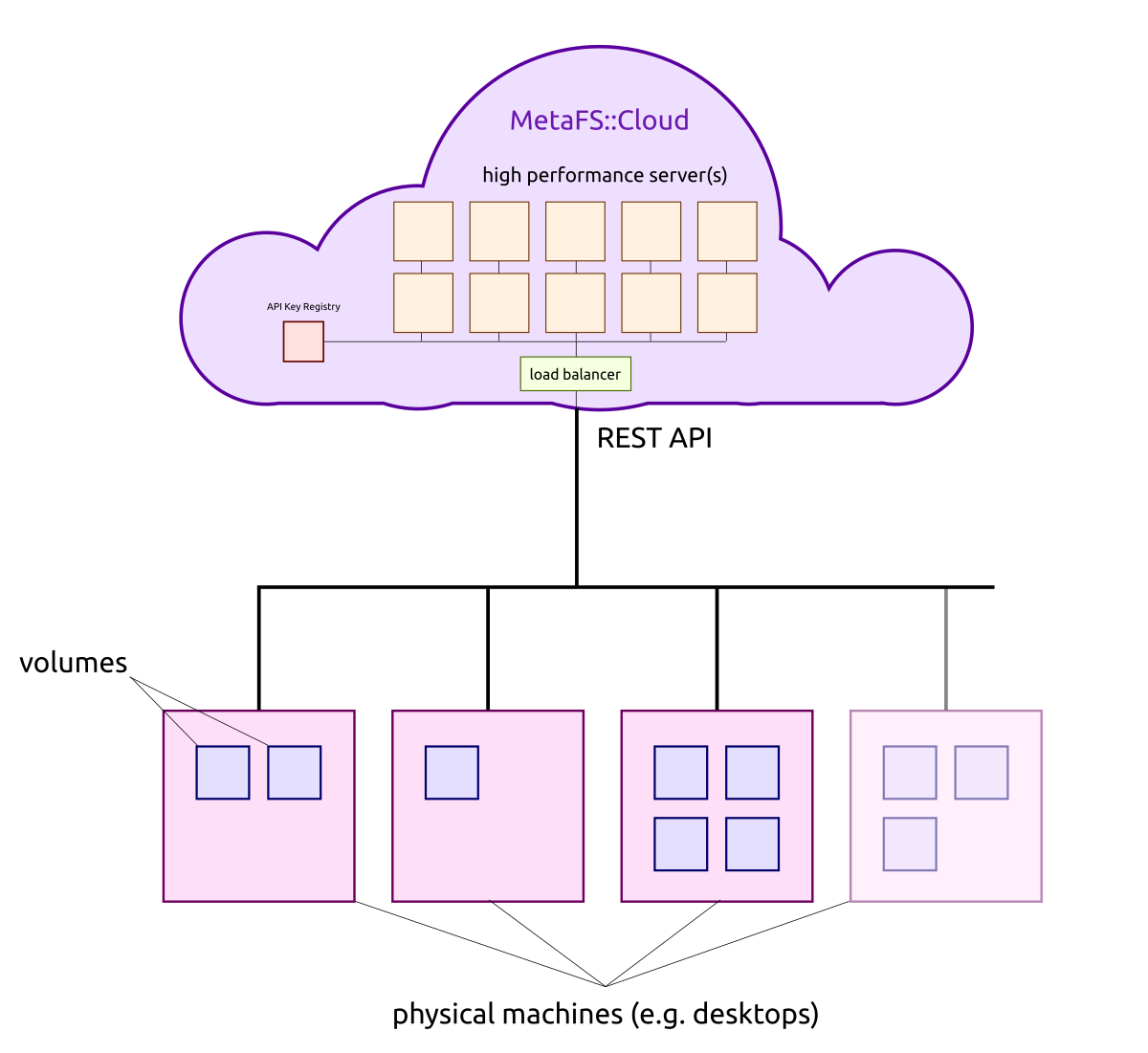
And with such also more heavy weight semantic analysis has been integrated preliminary:
faces: recognize faces (and train new faces) in imagesimagetags: image tagging, recognize various elements of the imagecaption: image caption, general impression of the overall imagedensecap: detailed or deep image caption
sentimentstopicsentitiesmusic
Semantics Extended
posted 2016/04/05 by rkmNew semantics handlers:

entities: recognizes individuals, organizations and companies (~20,000 entities) based on DBpedia.org and Wikidata.org and hand-picked sources.music: concludes rhythm (bpm), tonality, genres, vocal/instrumental, moods using Essentia.
Entities example:
% mmeta --entities "Amateur Photographer - 2 April 2016.pdf"
entities: [ Nikon, Canon, Olympus, Panasonic, Sony, BP, Facebook, SanDisk, Twitter, Ricoh, Bayer, Hoya, "Jenny Lewis", "Muhammad Ali", Visa, "Ansel Adams", DCC, Eaton, Empire, Google, "Konica Minolta", "Leonardo da Vinci", "Neil Armstrong" ]
Music query examples:
% mfind topics=jazz
... anything related to jazz: text, image, audio etc
% mfind audio.music.rhythm.bpm=~120
... just music with about 120bpm (beats per minute)
% mfind semantics.music.gender=male
... music with male voice
% mfind semantics.music.genres=disco
... just disco for The Martian
Partial Rewrite of the Core
posted 2016/02/28 by rkmAfter an extended "alpha" phase the "beta" state now lead to a rewrite of the core functionality to
- increase IO speed
- increase overall stability and reliability
MetaFS Paper Published (Preview)
posted 2015/12/05 by rkm
MetaFS Paper (PDF) published.
The paper describes MetaFS briefly and summarizes what About features and the Handbook and the Cookbook describe in more details.
IndexDB & Semantic Handlers
posted 2015/10/30 by rkm
- IndexDB 0.1.26: closing the gap to MongoDB in regards of functionality, improved stability, updated documentation:
- optional trigram indexes for fast regular expression queries, instead of 9secs (full index scan) now 0.6secs for 5 character long regex on 1.5M entries.
- update method
setsupported, required for atomic updates in MetaFS::Item
- Semantics: new handlers:
topicsbasic text topicalizer started, heading to integrate larger ontology (Wordnet, DBpedia, YAGO)ocrimage OCR (Optical Character Recognition) to convert scanned pages into text
- Handlers:
htmlimproved to cover general xml parsing as wellpdfsupportsexplodeevent type, which extracts all pages as images as sub-nodes; in combination ofocrsemantic handler very usefuldocx(new) preliminary OpenXML (Microsoft) support
- metafs (FUSE), metabusy: 0.5.4 few bug fixes
- Web GUI: 0.0.6 supporting
tags, andtext.topics
Updating Web-Site
posted 2015/09/12 by rkm
Even though the development continues non-public, I update the web-site and extend the documentation, e.g. Programming Guide.
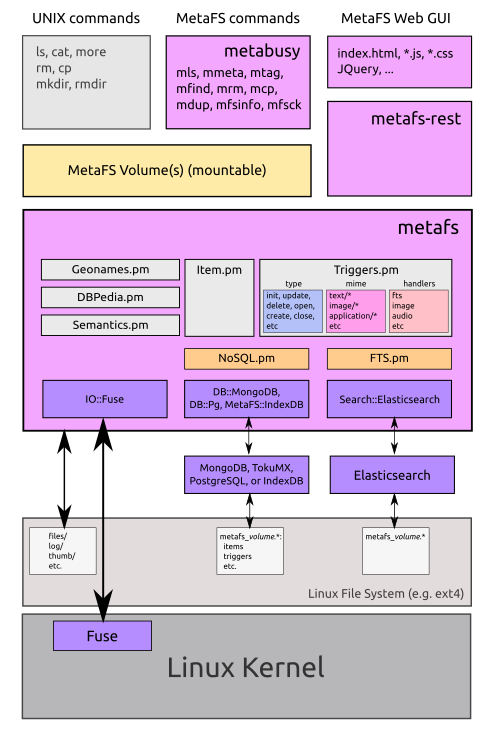
- IndexDB: 0.1.21 with bx storage engine is stabilizing, and reached the range of speed of MongoDB-3.x, partially even faster than MongoDB while using a fraction of the memory, benchmarks will be posted later.
- metafs (FUSE): 0.5.1 little update made in the core, most of NoSQLfying done (removed MongoDB specific code and introduced a proper NoSQL layer so other database such as IndexDB can be used), mainly working on the IndexDB the past weeks and months.
- metafs-rest: 0.0.11 NoSQLified as well, fine-tuning for the Web-GUI
- Web GUI: 0.0.4 significantly improved search capability, screencasts and screenshots will be posted later.
Working on Stable
posted 2015/08/04 by rkm
Comprehensive refactoring of has started, de-couple former MongoDB centric code to use more abstract NoSQL layer which allows then to use multiple backends instead of MongoDB. For the time being the development of beta is non-public and eventually replace the former alpha (proof of concept).
beta is expected early 2016.
MetaFS::IndexDB
posted 2015/07/18 by rkmMetaFS::IndexDB development has started and first steps for integration into has begun. Eventually it will be released in 2016 with beta, the preliminary API has been published.
IndexDB lifts some of the limitations of the other backends:
- full indexing of metadata
- low memory usage
- predictable response time
- multiple low-level DB engines
File Browser & Image Query Screencast
posted 2015/05/11 by rkmTwo brief screencasts to show the early state of web-frontend to test the backend of MetaFS:
Note: the Location experiment with "Berlin" are two steps: 1) look up GPS coordinate of "Berlin" and 2) search with those coordinate in the MetaFS volume for GPS tagged items like photos.
Backend: MetaFS-0.4.10 with MongoDB-3.0.2 WiredTiger on a Intel Core i7-4710HQ CPU @ 2.50GHz (4 cores) with 16GB RAM, running Ubuntu 14.10 64 bit.
MongoDB is working "OK", it could be better, some queries with additional post sorting cause immense memory usage and cause slow down. So for casual testing MongoDB is "OK", but MetaFS::IndexDB or PostgreSQL with better JSON support are still prefered once they are mature enough.
General Query
posted 2015/05/10 by rkmSome early tests of a 2D Web-GUI to cover the complexity of querying items:
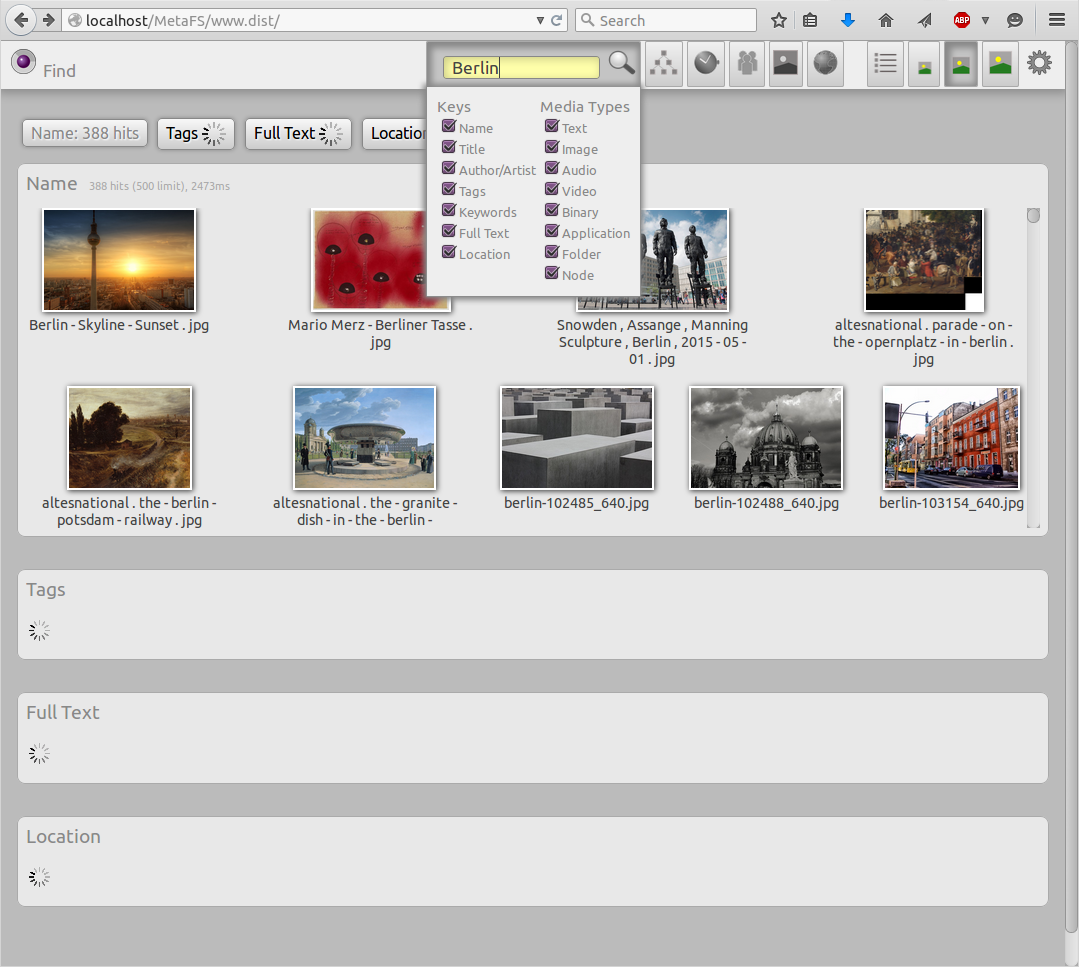
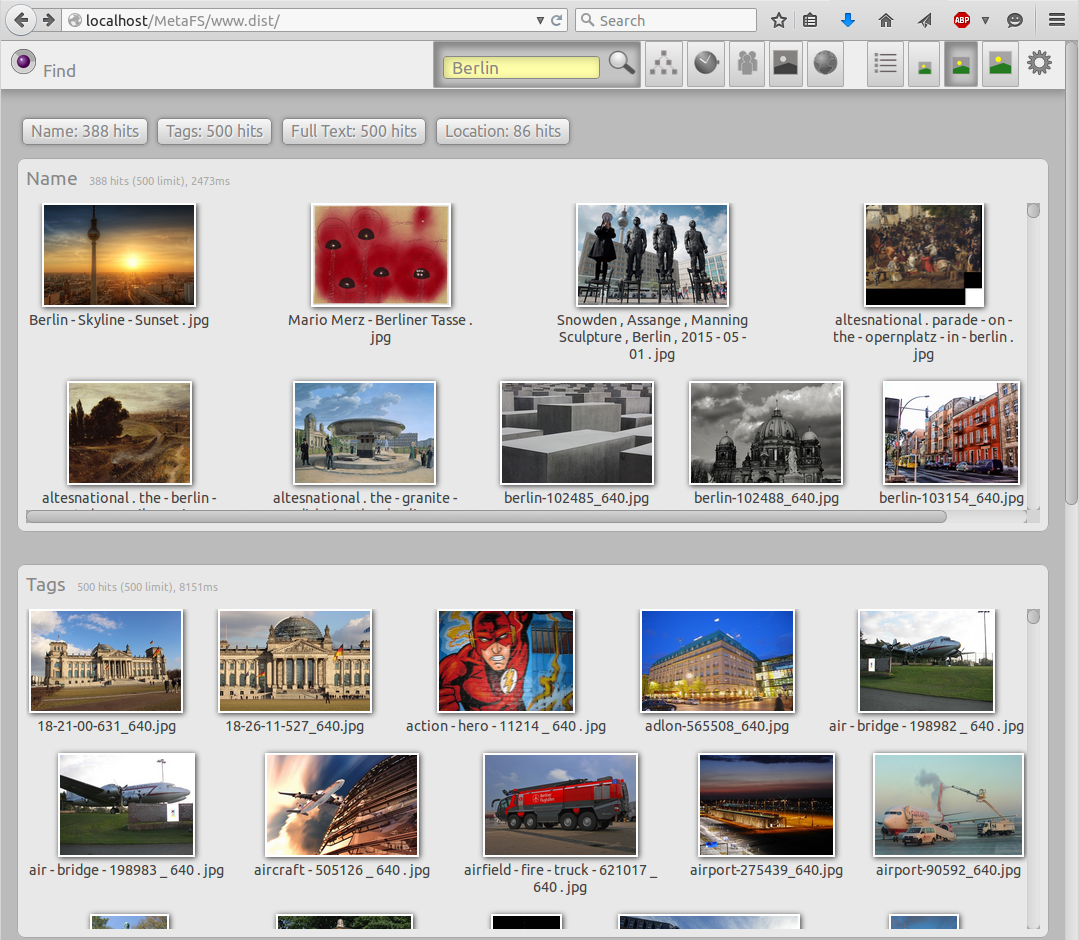
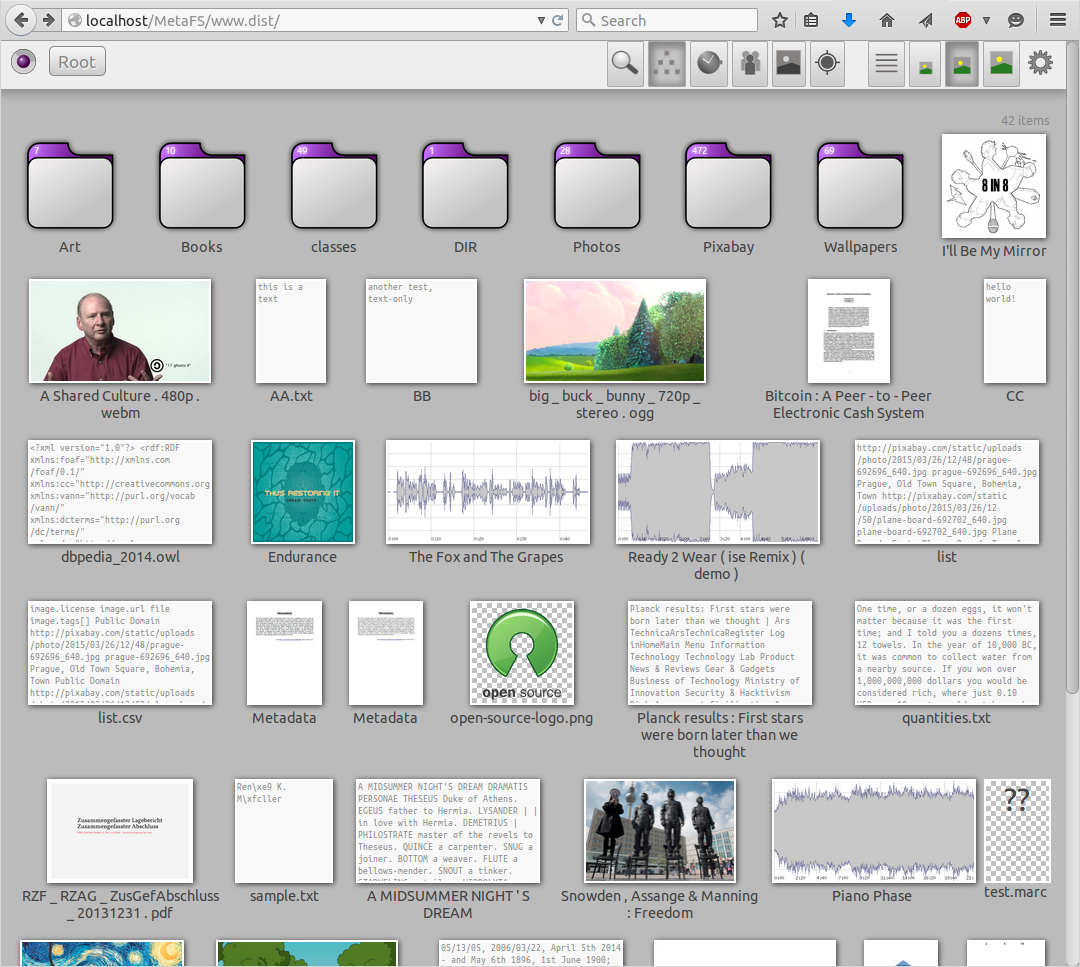
I queried "Berlin" as example so the Location would provide results as well, "Berlin" is a known location, and some photos have GPS location and those are found too.
The volume was mounted on a HDD not SSD, the lookup time on SSD is about 5-10% of a HDD.
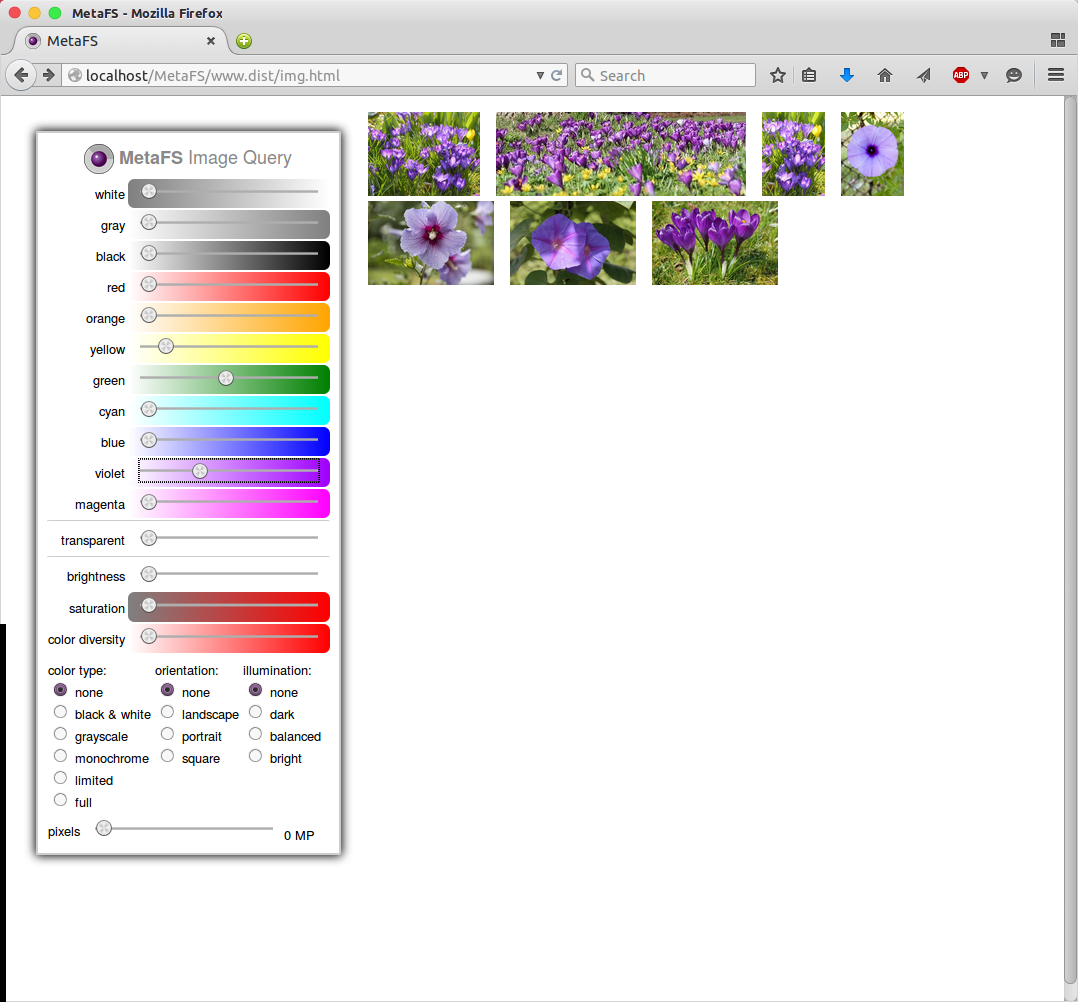
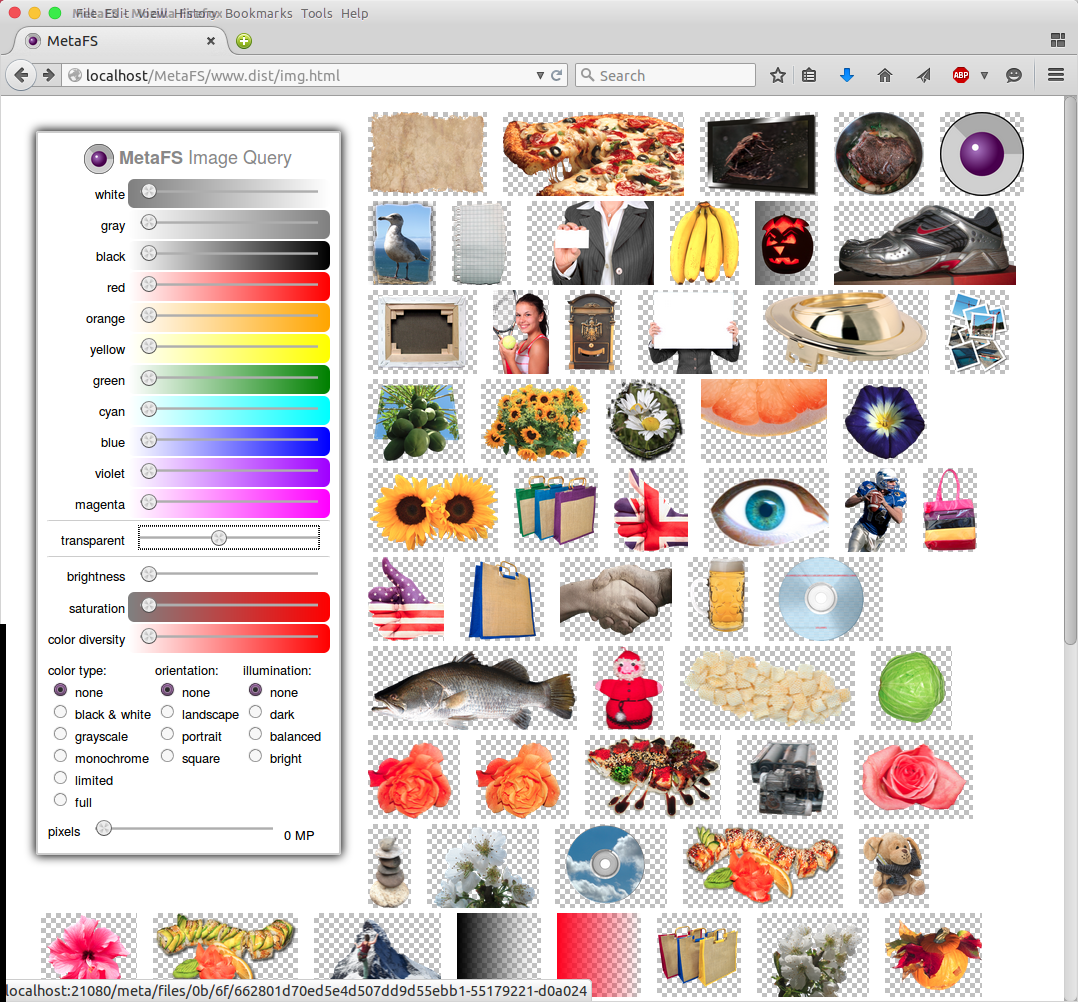
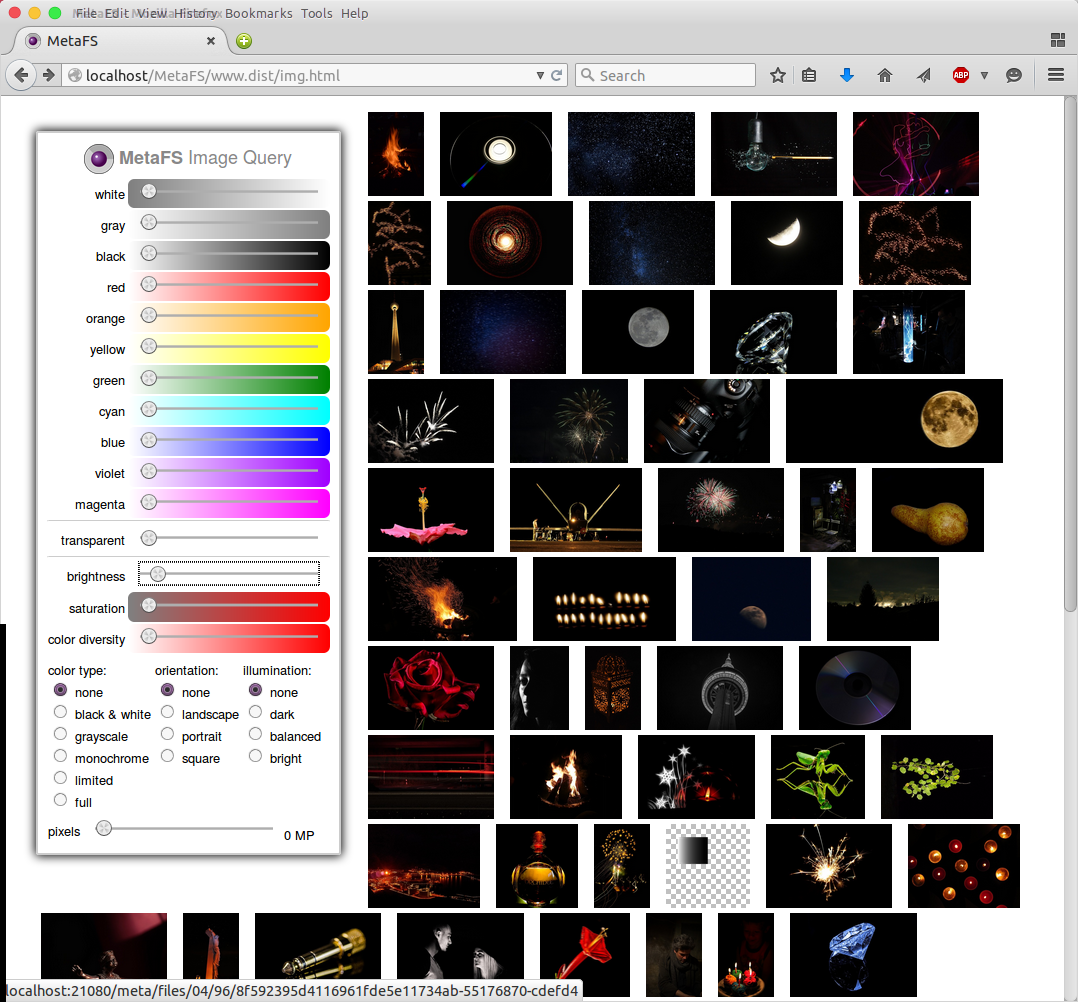
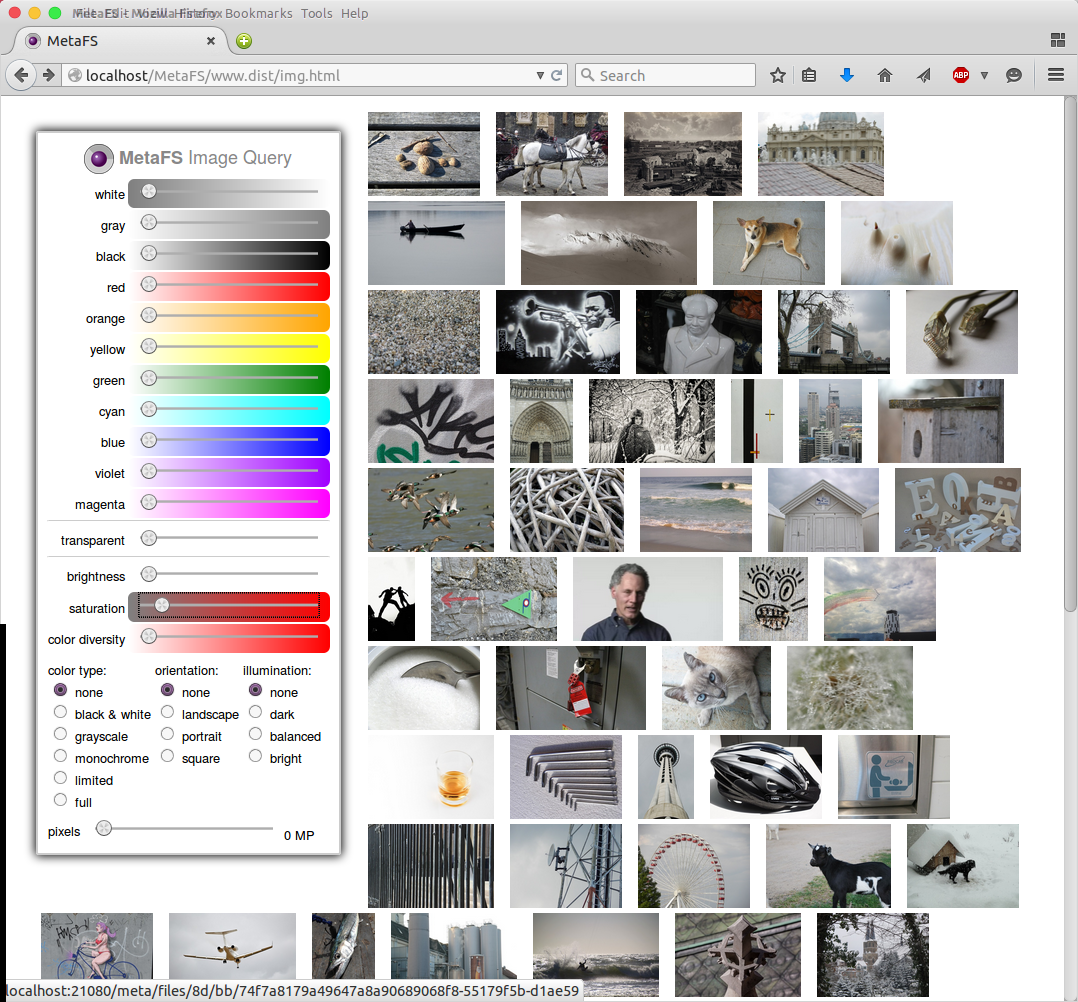
Image Query
posted 2015/04/29 by rkm
In order to test image indexing (image-handler) a rudimentary interface is used to query a set of 280,000 images:
- diverse colors
- brightness
- saturation
- color diversity
- several types
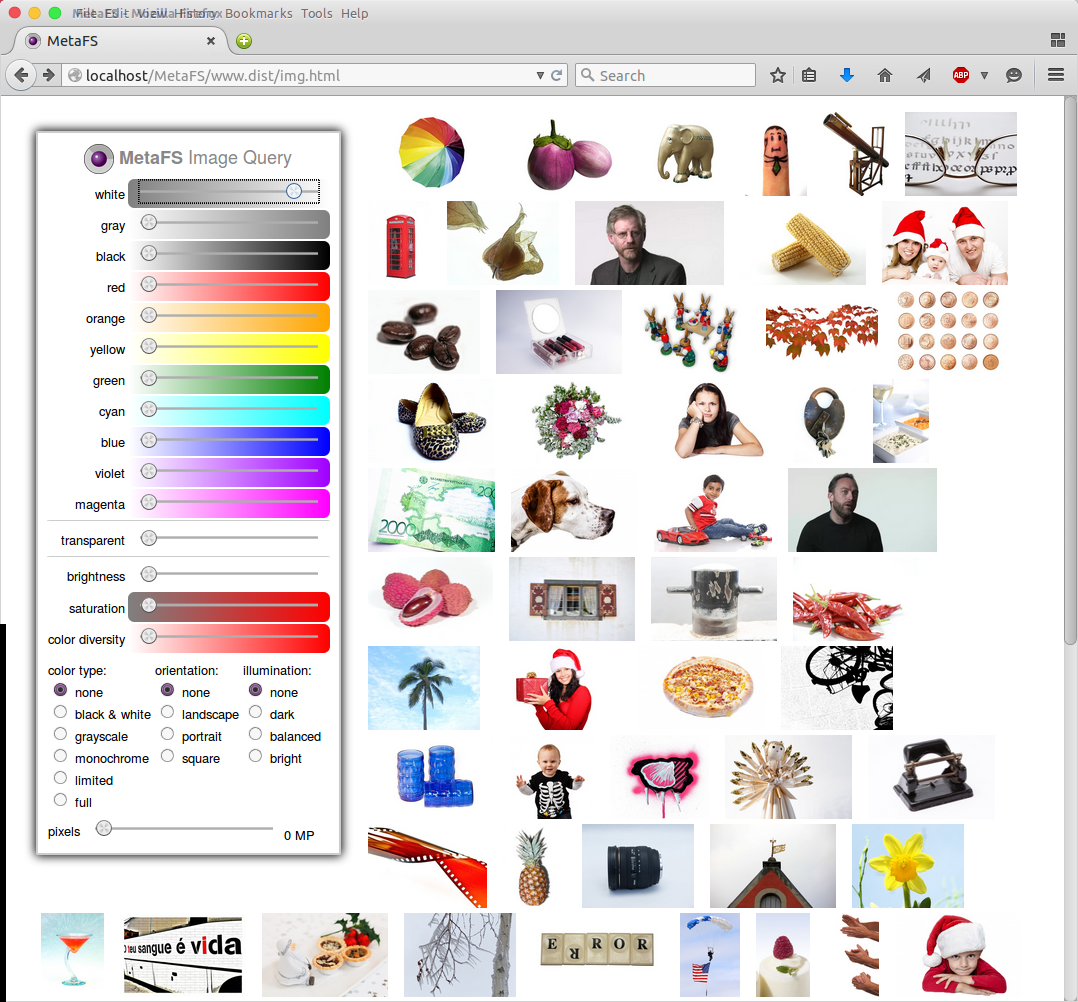
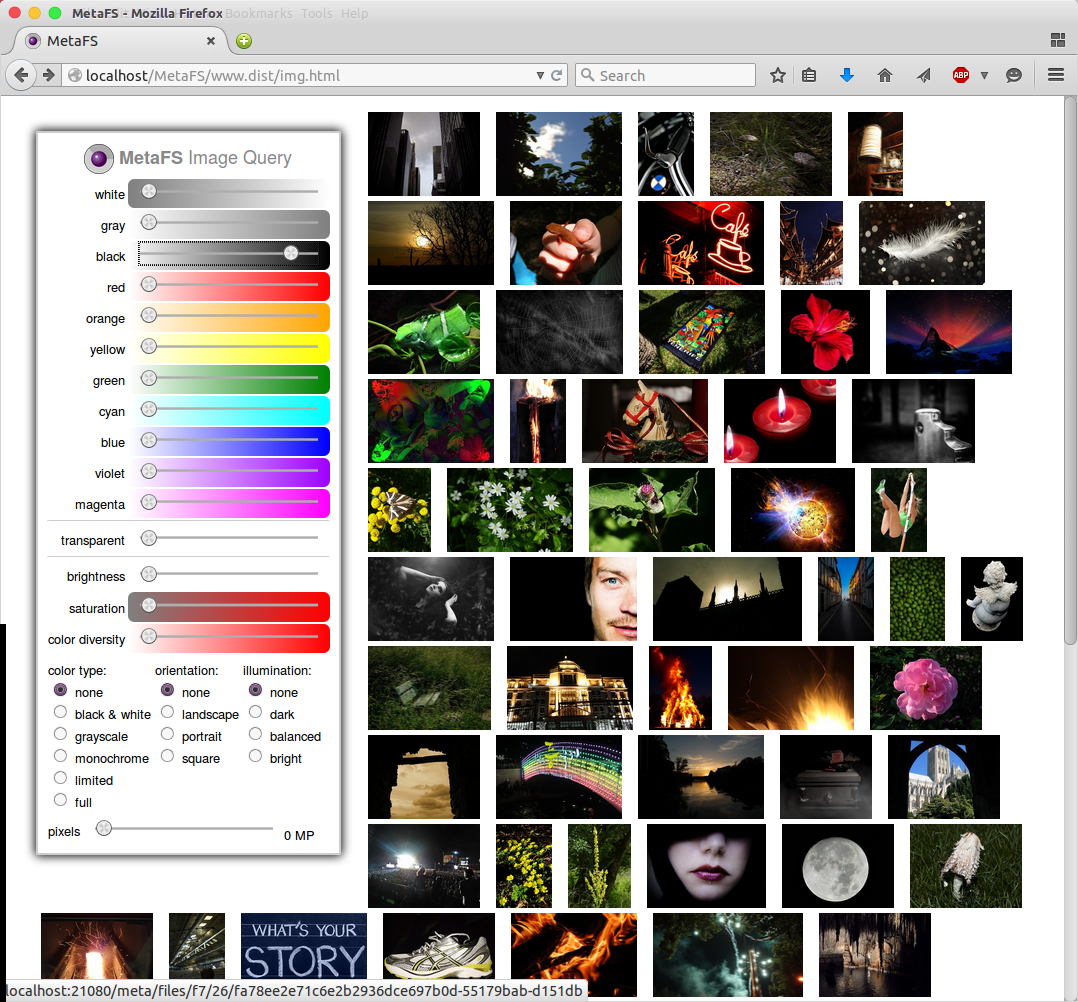
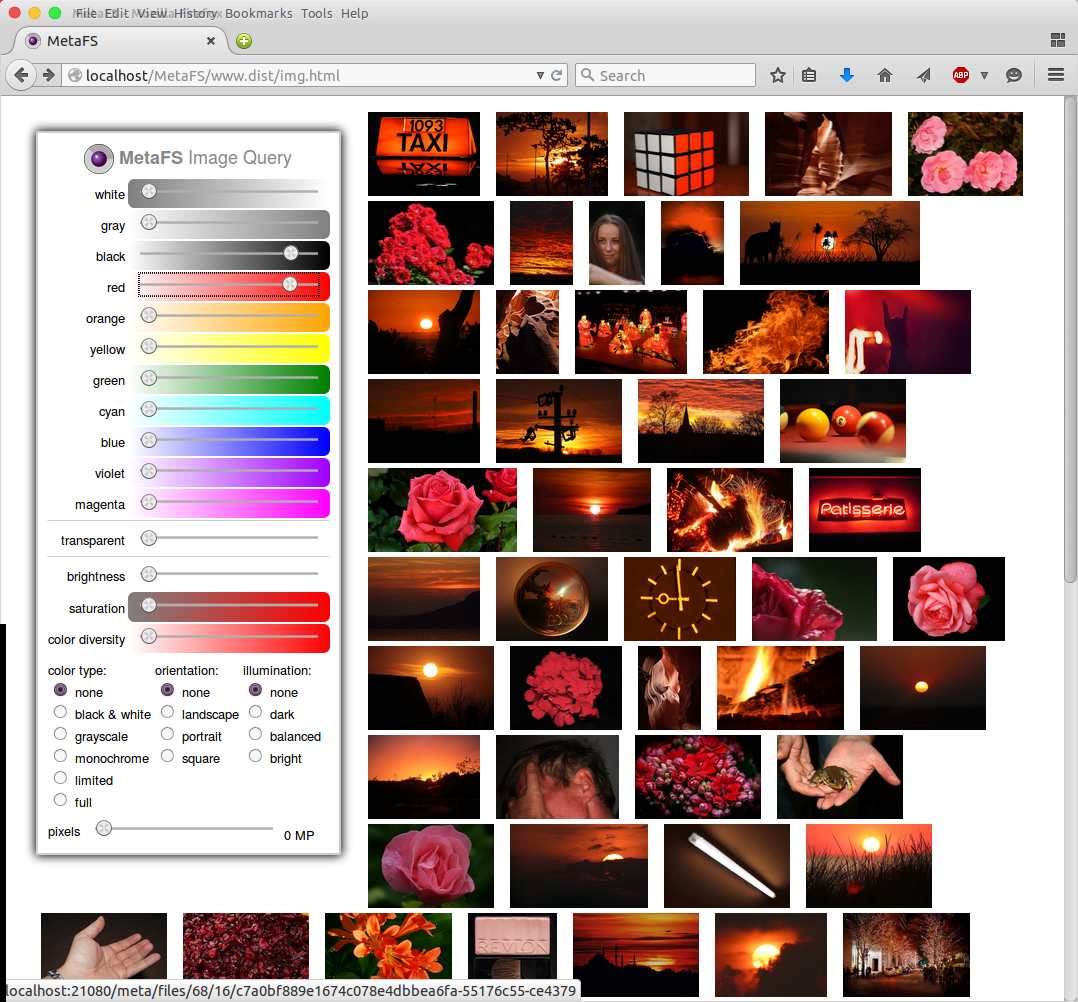

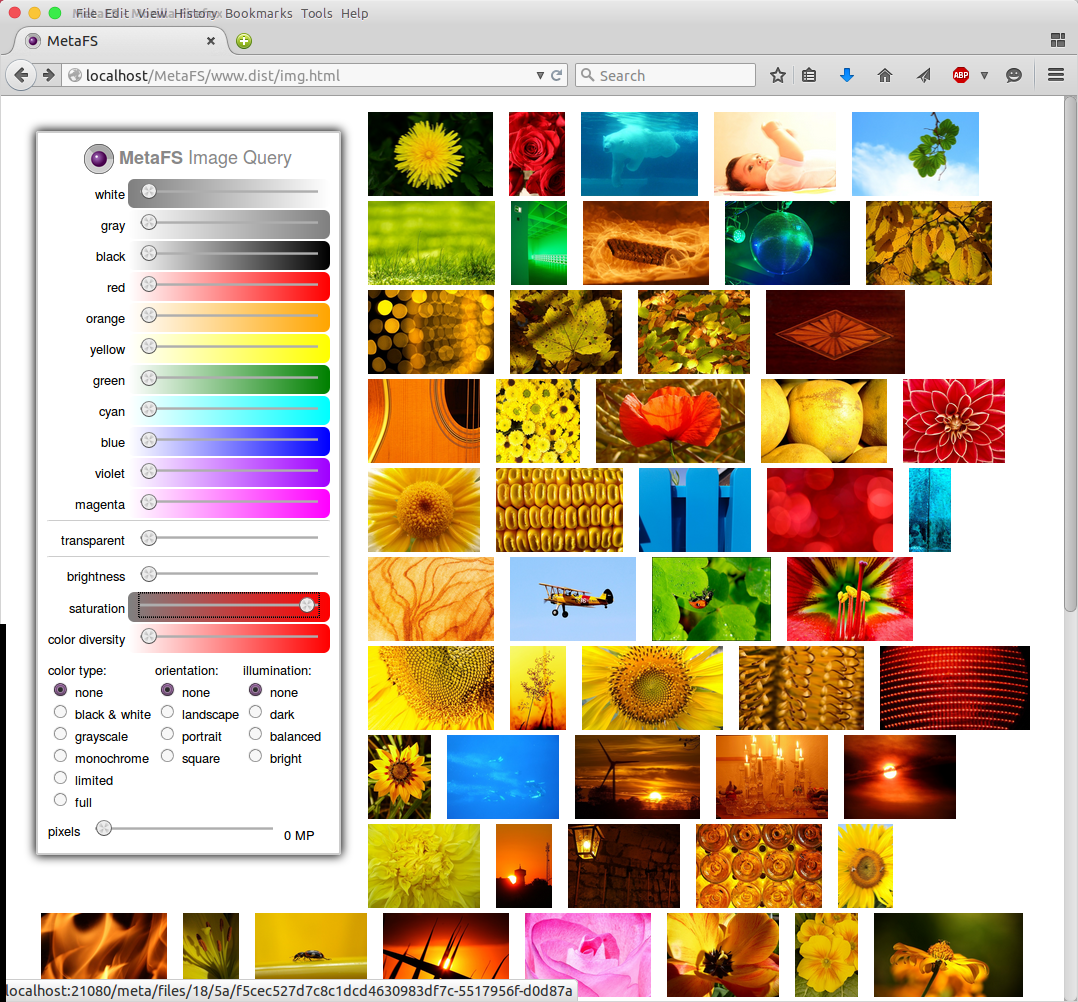
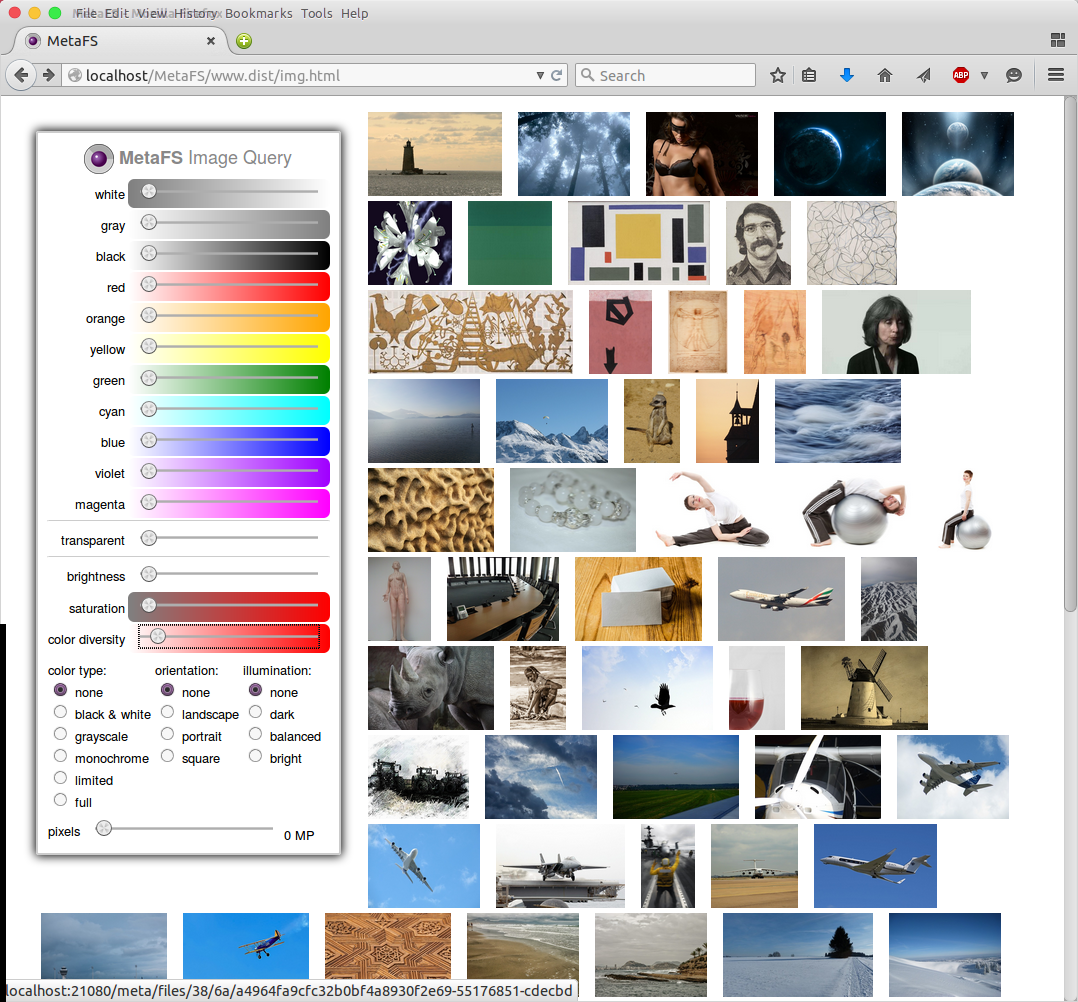
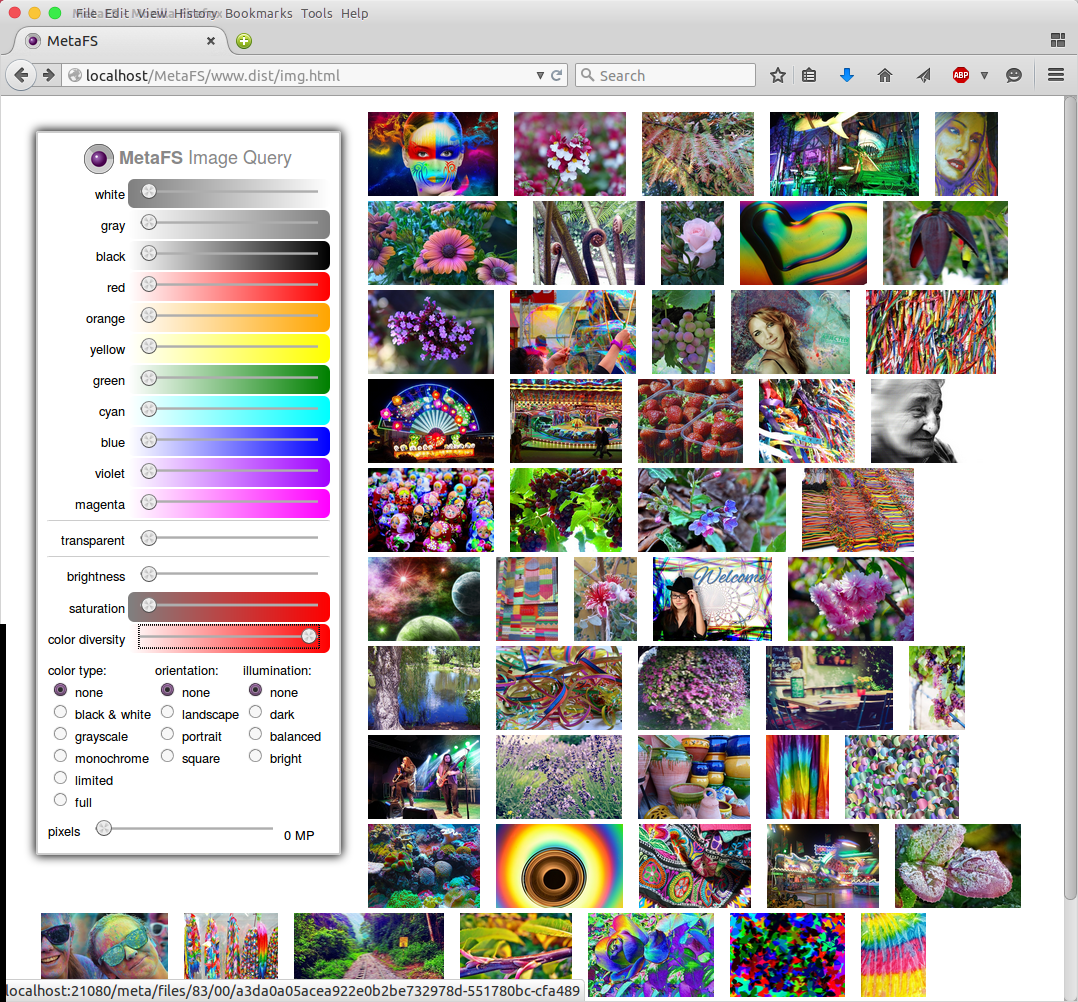
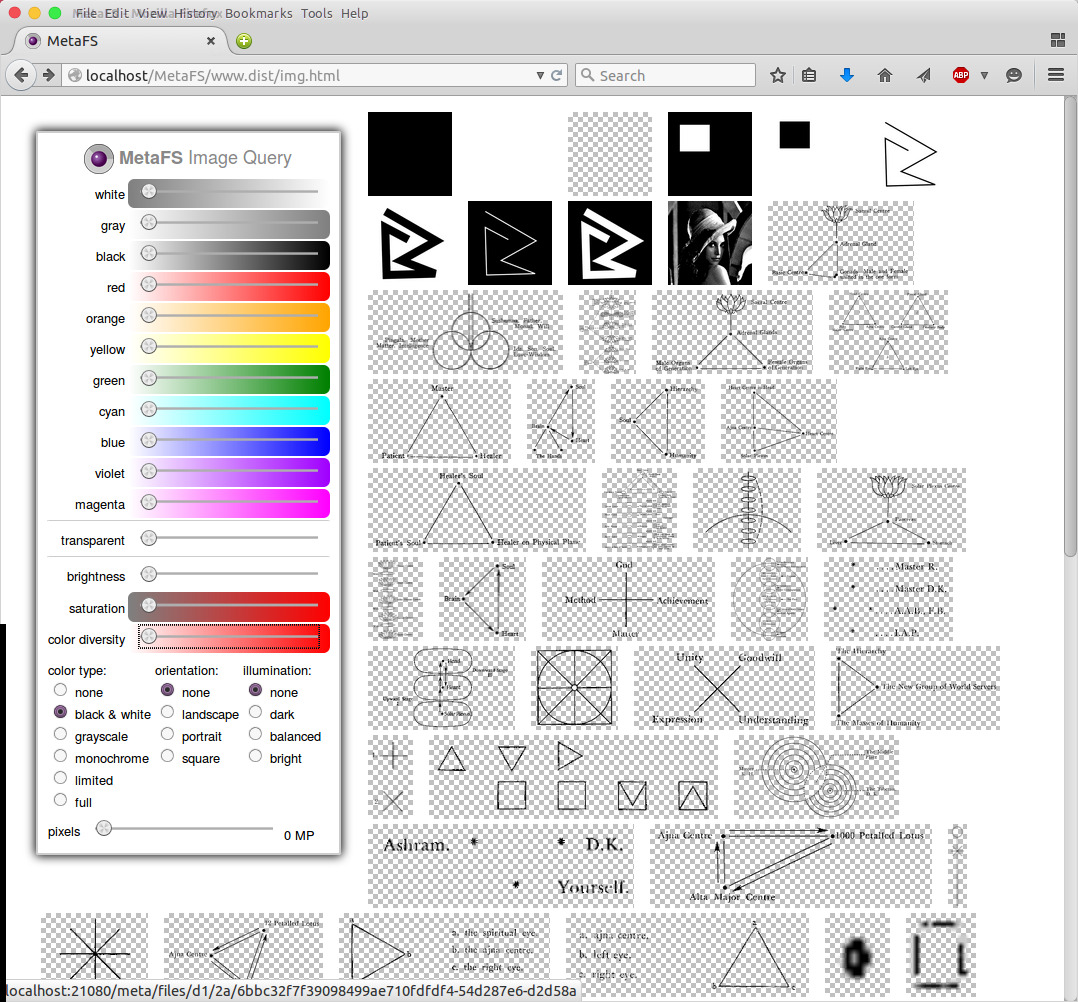
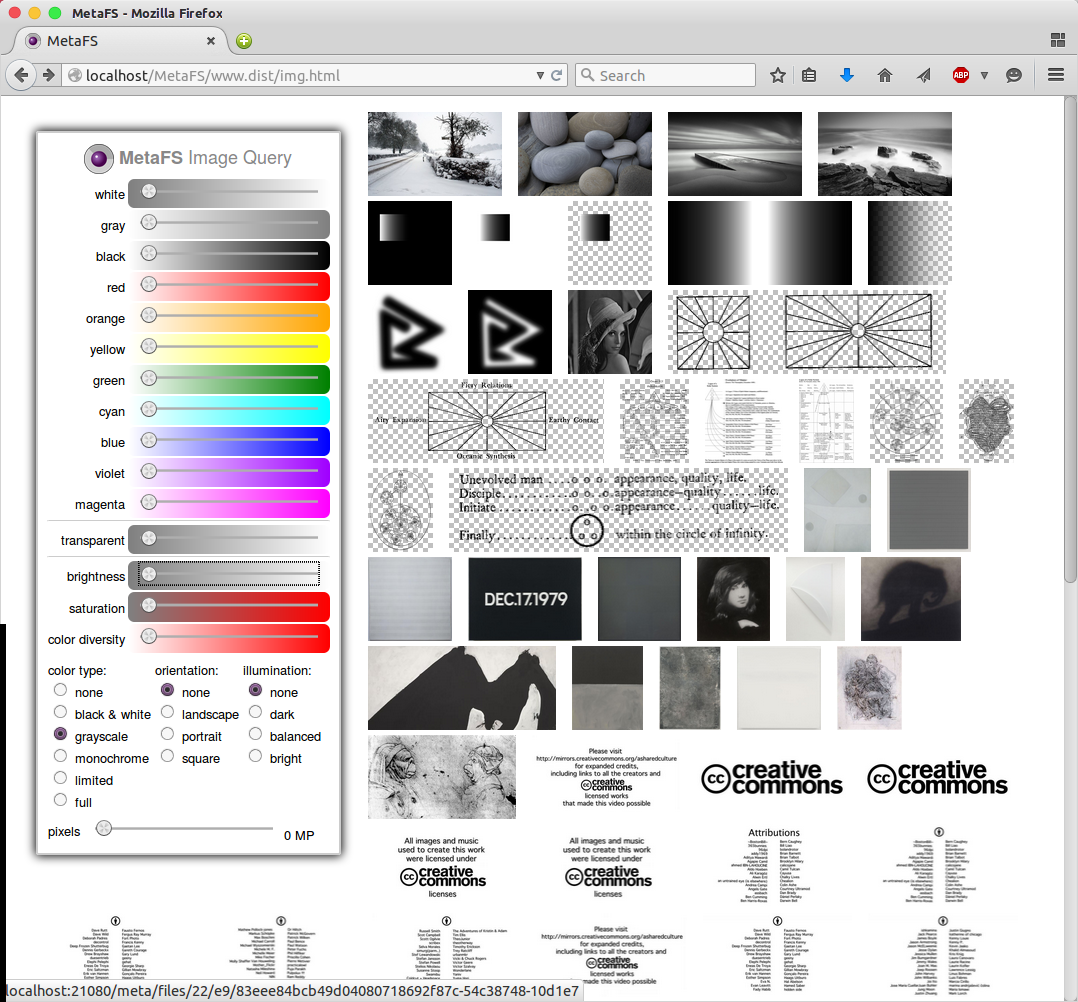
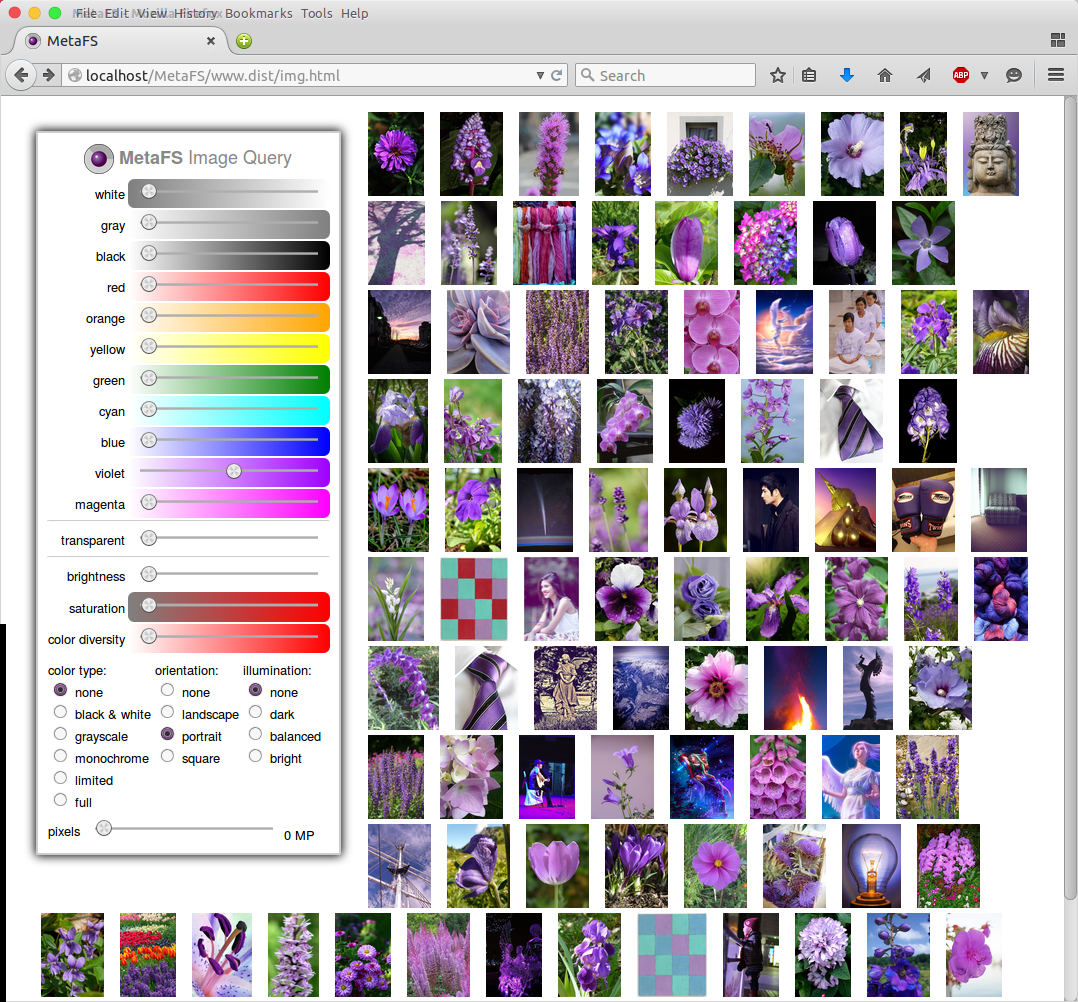
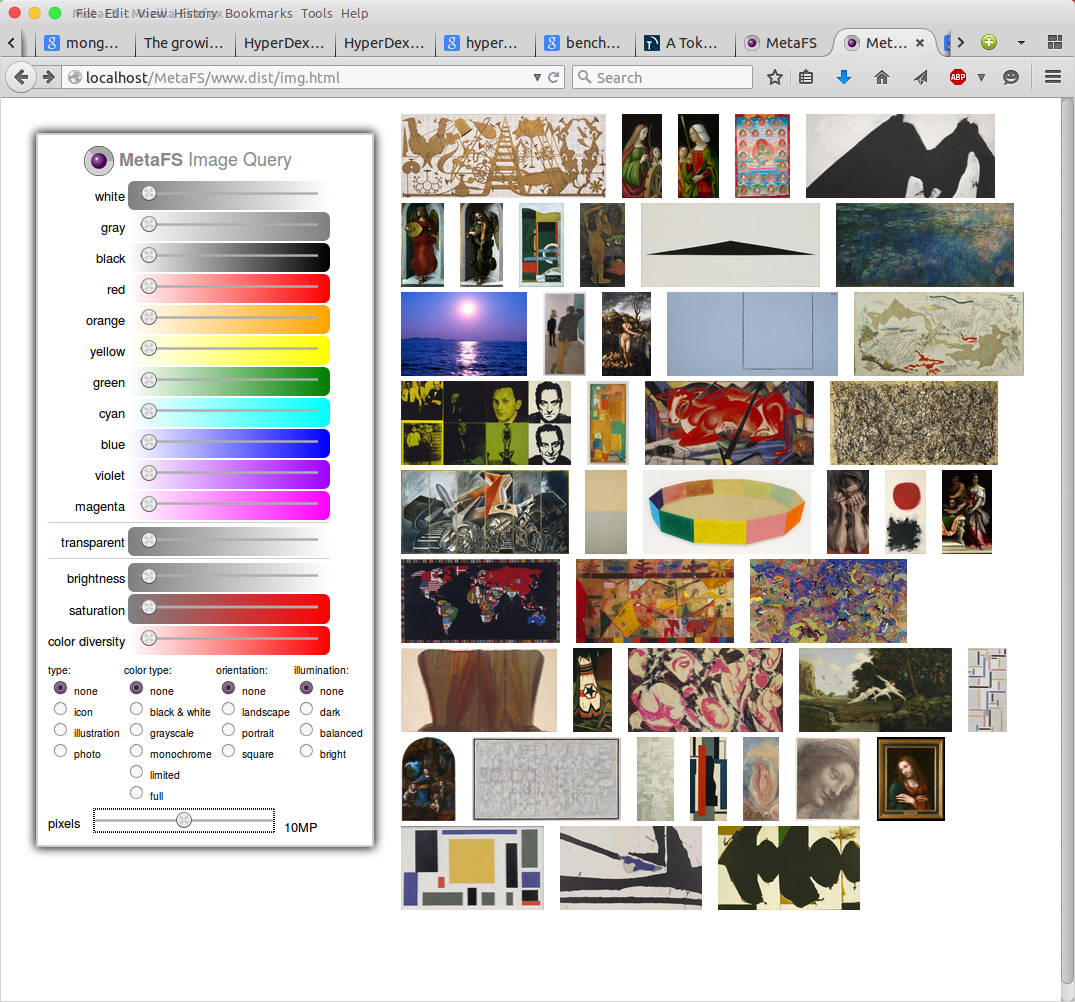
Web interface will be released later along with a general "data-browser" UI.
Changelog 0.4.9
posted 2015/04/26 by rkm
metafs.confand other *.conf can containindexingsection where keys are listed with their indexing-priority:- essential (immediately indexed)
- important (can be indexed a bit later)
- must-have (can be indexed later)
- optional (nice to have)
indexing-sections are only considered currently by MongoDB (mongo) backend (default), priorities 1-3 covered totaling ~59 keys (64 indexes max)
- preliminary (very experimental & unstable) PostgreSQL-9.4.1
pgbackend support using JSONB (jsonb_path_ops) GIN indexing which indexes all keys by default, doesn't support inequality queries yet (essential missing feature),mfindnot yet supported:
but you require (for now) to manually create the SQL database for the volume (in this example% metafs --backend=pg alpha Alpha/ % cd Alpha/ % lsalpha) in PostgreSQL beforehand:% sudo -u postgres psql postgres=# create database metafs_alpha postgres=# \q
- preliminary
expose.indexDirsfeature:onoroff(default), listing indexes as directories one can dive into (for now nomlsand othermetabusy-tools support) and read access (no write yet) under@/:% metafs --expose.indexDirs=on alpha Alpha/ % cd Alpha % ls @/ BB DIR/ open-source-logo.png* Untitled.odg* zero.bin 20130914_140844.jpg* bitcoin.pdf fables_01_01_aesop_64kb.mp3 shakespeare-midsummer-16.txt Untitled.ods* AA.txt CC Metadata.odt* timings.txt violet_sunset.jpg* % cd @ % ls atime/ author/ hash/ keywords/ mime/ name/ parent/ tags/ title/ uid/ video/ audio/ ctime/ image/ location/ mtime/ otime/ size/ text/ type/ utime/ % cd image average/ color/ height/ orient/ pixels/ theme/ type/ variance/ width/ % cd orient % ls landscape/ portrait/ square/ % cd square/ % ls 2dbaeffc27f5d7afc38b6a31a9ca9307-553be760-0d0a9b#open-source-logo.png ...
- better or easier manual command-line configuration:
for using MongoDB running at e.g. port 27020 (default 27017), simplifies running multiple MongoDBs (MongoDB 2.6.1, MongoDB 3.0.2 MMAPv1 or WiredTiger) or MongoDB-compatible DBs (TokuMX or more mature ToroDB) without requirement for dedicated% metafs --mongo.port=27020 alpha Alpha/ % cd Alpha/ % lsmetafs.conffor each volume.
MongoDB vs Others
posted 2015/04/24 by rkmThe default backend of is MongoDB, a quasi standard NoSQL database. Yet during testing the "proof of concept" some significant short-comings showed up:
- only 64 indexes per collection
- memory usage can be significant
- memory usage cannot be controlled
| MongoDB-3.0.2 | TokuMX-2.0.1 | PostgreSQL-9.4.1 | MetaFS::IndexDB-0.1.7 | |
| NoSQL state: | mature | mature | inmature[1] | experimental |
| ACID: | no | yes | yes | no[2] |
| internal format: | BSON | BSON | JSONB | JSON + binary |
| inequality functions: | full | full | none[3] | full |
| memory usage: | heavy[4] | heavy | light | light |
| control memory usage: | no[5] | yes | yes | no |
| max indexes: | 64 | 64 | unlimited | unlimited |
| insertion speed:[6] | fast (2000/s) | fast (2000/s) | moderate (200/s) | moderate (200/s) |
| lookup speed: | slow - fast[7] | slow - fast[8] | fast | fast |
| sorting results with another key: | no / yes[9] | no / yes[10] | yes | no |
- PostgreSQL-9.4.1 doesn't support in-place key/value updates yet
- IndexDB-0.1.7 doesn't support transactions yet, but is planned
- Postgres-9.4.1 with GIN index supports no inequality comparisons
- MongoDB-3.0.2 virtual memory usage can be huge (hundreds of GBs), resident memory use 10-20% of physical RAM
- MongoDB-3.0.2 let's the OS control the overall memory usage
- tested on the same machine (4 core, 16GB RAM, 256 GB SSD)
- MongoDB-3.0.2, lookup speed depends whether key is indexed
- TokuMX alike MongoDB
- MongoDB-3.0.2: only when key is indexed
- TokuMX-2.0.1: only when key is indexed
Efforts to immitate NoSQL of MongoDB with PostgreSQL backend:
- ToroDB (state 2015/02): distribute key/value to dedicated tables, Java-based, upsert not yet supported, 0.4.9 failed at startup therefore
- Mongolike (state 2014/08): create/drop collection, save, find, runCommand, ensureIndex, removeIndex, getIndexes
- Mongres (state 2013/05, abandoned): find & insert
- low memory usage: it's a "rich" filesystem, yet, it can't or shouldn't use significant portions of memory by itself
- fast lookup: once the data is inserted into the filesystem (and indexed) it should be fast to lookup, hence, the fully indexed approach:
- fully indexed: preferable all keys are indexed[1]
- fast insertion: still important but not 1st priority is decent speed to insert, yet, insertion has several steps:
- insertion of data & metadata,
- indexing of the metadata,
- extraction of metadata from the data from handlers (delayed/queued execution)
I will update this blog post with updates when other DBs are considered and benchmarked.
Fully Indexed DB Tests
posted 2015/04/12 by rkmupdated 2015/04/22 by rkm: Adding Postgres-9.4.1 with GIN index benchmark.
Background
The "proof of concept" of (0.4.8) with MongoDB-2.6.1 (or 3.0.2) has a limit with 64 indexes per collection (which is the equivalent of a volume) which is too limiting for real life usage. To be specific, 64 keys per item (and being indexed) might sufficient, yet, there are different kind of items with different keys so 64 keys for a wide-range of items are reached quickly:
- base: 16 keys (name, uid, ctime, atime, mtime etc)
- text: 6 (essential) + 9 (optional) = 6..15 keys
- image: 7 (essential) + 12 (base) + 8 (optional) = 19..27 keys
- audio: 7 keys
- video: 6 keys
- location: 2 (essential) + 2 (base) = 4 keys
- semantics: 3..10 keys (different levels)
Setup
Machine has an Intel Core i7-4710HQ CPU 2.5GHz (4 Cores), 16GB RAM, 256GB LITEON IT L8T-256L9G (H881202) SSD running Ubuntu 14.10 64 Bit (Kernel 3.16.0-33-generic), with CPU load of 2.0 as base line; in other words, an already busy system is used to simulate more real world scenario.
Two test setups are benchmarked with 1 mio JSON documents where all keys are fully indexed:
- MetaFS::IndexDB-0.1.7: client/server setup (comperable to Postgres), 40+ keys indexed
- Postgres-9.4.1 dedicated key indexes: JSON data type with ~37 keys dedicated indexed
- Postgres-9.4.1 GIN: JSON data type with ~37 keys indexed with GIN
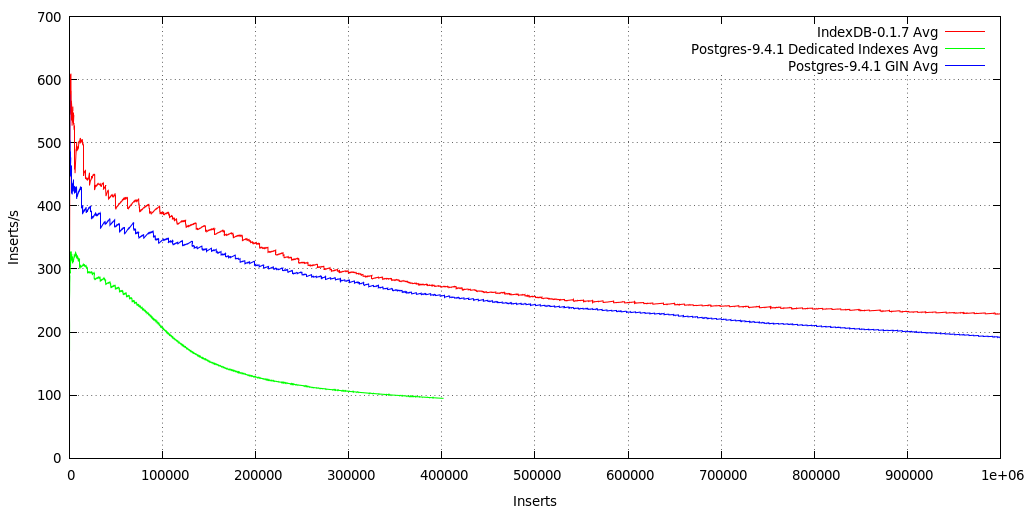
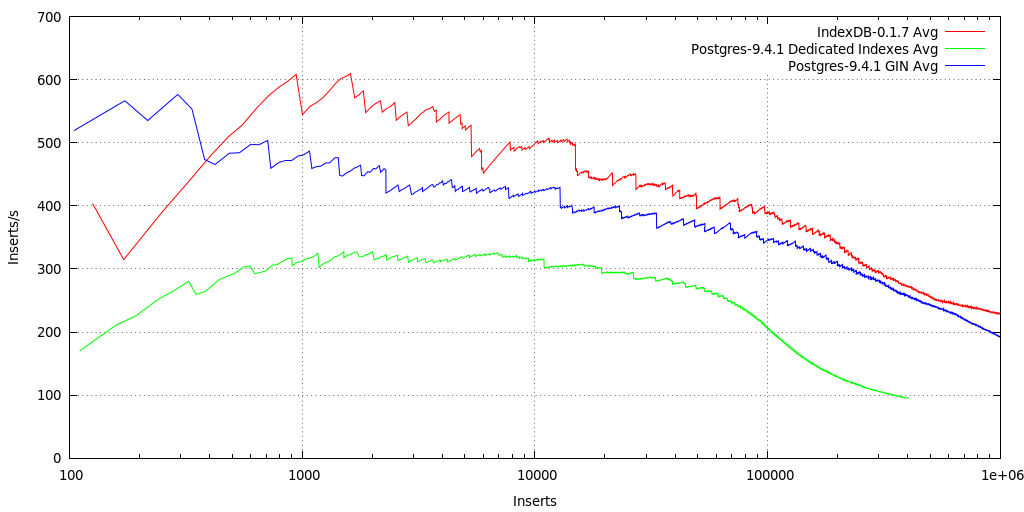
MetaFS::IndexDB-0.1.7, a custom database in development for using BerkeleyDB 5.3 B-Tree as key/value index storage, saving JSON as flat file, starts fast with 600+ inserts/s and then steadily declines to 230 inserts/s after 1 mio entries.
Postgres-9.4.1 with dedicated keys indexes performs for the first 100K entries quite well and then steeply declines to 95 inserts/s, after 400K entries benchmark aborted. Since 9.4 there are NoSQL features included, see Linux Journal: PostgreSQL, the NoSQL Database (2015/01).
CREATE TABLE items (data JSONB)
INSERT INTO items (data) values (?)
INSERT INTO items (data) values (?)
INSERT INTO items (data) values (?)
...
CREATE INDEX ON items ((data->>atime))
CREATE INDEX ON items ((data->>ctime))
CREATE INDEX ON items ((data->>mtime))
CREATE INDEX ON items ((data->image->>width))
CREATE INDEX ON items ((data->image->>height))
CREATE INDEX ON items ((data->image->theme->>black))
...
Postgres-9.4.1 with GIN (Generalized Inverted Index) indexes all JSON keys by default, no need to track the keys, and it performs quite well, alike to IndexDB; no surprise since both use B-Tree.
CREATE TABLE items (data JSONB)
CREATE INDEX ON items USING GIN (data jsonb_path_ops)
Conclusion
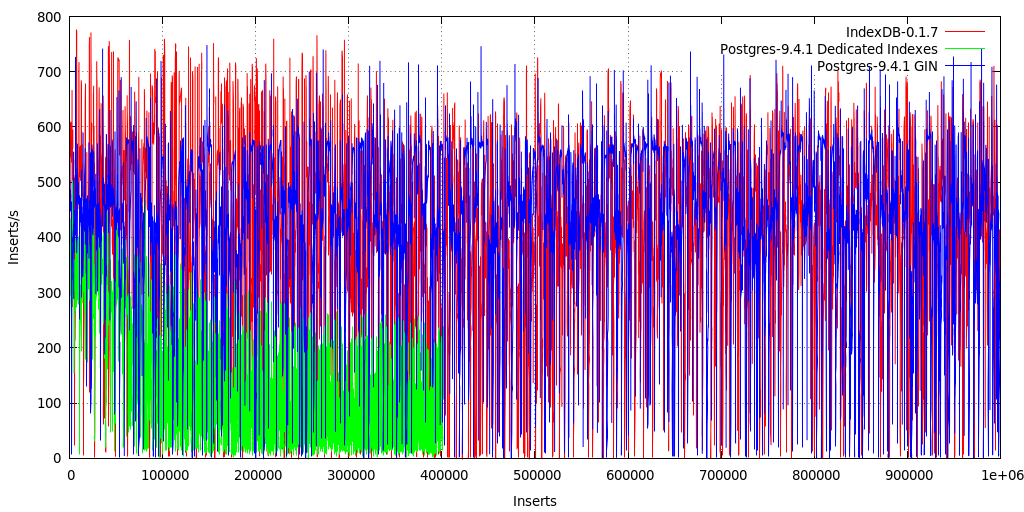
The "5s Average" reveals more details: MetaFS::IndexDB inserts remain fast alike Postgres with GIN, yet, the syncing to disk every 30 secs (can be altered) with IndexDB gets longer and CPU & IO intensive and causing the overall average to go down, whereas Postgres with dedicated keys falls quicker and likely syncing immediately to disk (has 5 processes handling the DB), and is less demanding on the IO as the system remains more responsive.
IndexDB-0.1.7 supports inequality operators: < <= > >= != and ranges,
whereas Postgres-9.4.1 with jsonb_path_ops only can query (SELECT) on value or existance of keys, but not inequalities yet.
Outlook
With every key additionally indexed the amount of to be written data increases: O(nkeys). Additionally, BerkeleyDB documentation regarding BTree access method:
Insertions, deletions, and lookups take the same amount of time: The time taken is of the order of O(log(B N)), where B equals the number of records per page, and N equals the total number of records.which the benchmark pretty much confirms.
If delayed indexing with MetaFS::IndexDB would be considered, the index time would still be depending on the actual amount of all items in a volume, but having faster inserts but delayed search capability on the full data. So depending on the use case or choice, either data becoming quickly searchable, or having constant insertion speed.
IndexDB might scale a bit better post 10mio items, as Postgres+GIN shows a slightly steeper decline in performance - but that has be confirmed with actual benchmarks.
Both DBs without indexing at all as comparison:
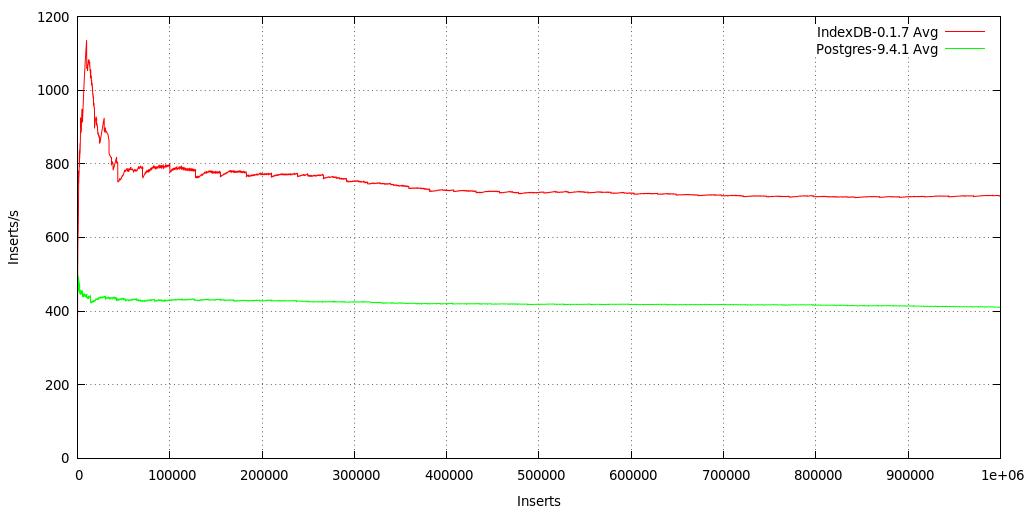
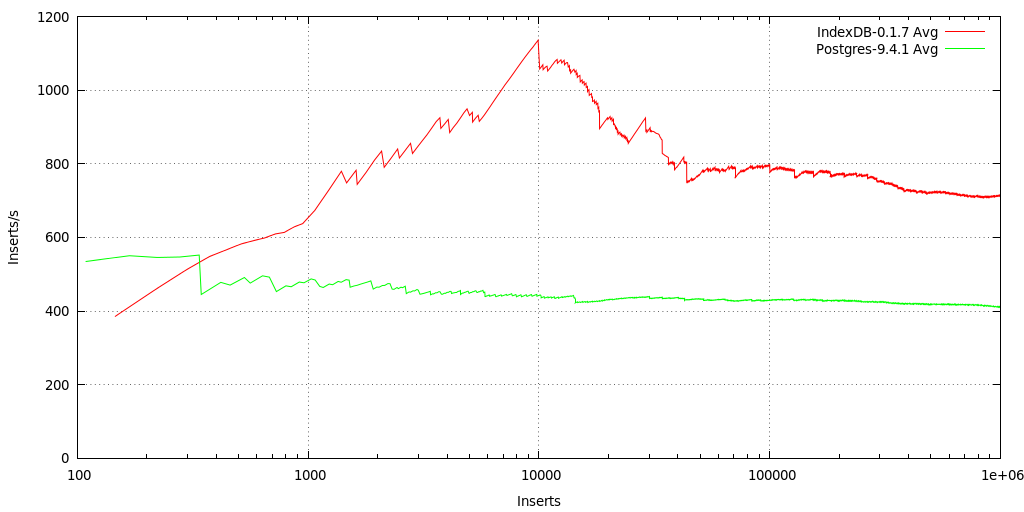
Postgres-9.4.1: stays around 410 inserts/s, MetaFS::IndexDB-0.1.7: starts slow (creating required directories, apprx. 256 x 256) and then increases in speed then drops to ~700 inserts/s after 200K. Both DBs stay constant after 100K inserts, MetaFS::IndexDB (1.5 - 1.7x) a bit faster than Postgres (1x). The 5s average (not shown) fluctuate between 200 - 1200 inserts/s for MetaFS::IndexDB, and 150 - 700 inserts/s for Postgres.
Image (Color) Theme
posted 2015/03/27 by rkm
The image-handler got a major improvement, actually it's not much code which I added, but the little code is quite impressive in its effect, for example:
You can search images based on their color theme, the main colors
- red, orange, yellow, green, cyan, blue, violet, magenta plus
- white, gray, black and
- transparent
image.theme.* and add up to 100% or 1.0

theme: {
black: 2.60%
blue: 30.88%
gray: 12.40%
green: 2.31%
orange: 21.85%
white: 20.17%
yellow: 9.18%
}
So, searching for ocean scenery with the sun present, a lot of blue, and sufficient yellow:
% mfind 'image.theme.blue>50%' 'image.theme.yellow>10%'

Let's try with tiny range of yellow:
% mfind 'image.theme.blue>50%' 'image.theme.yellow=1..3%'





Some yellow matches are obvious, the last image match is about the palms trunks and partially at the palm leaves: brown, the lower saturated yellow. So, you use the saturated color names, but the match includes lesser saturated and brighter aspects of that color - so keep this in mind in this context.
Although I've got the ocean (beach) scenery, there is no sun - perhaps orange would be more accurate:
% mfind 'image.theme.blue>50%' 'image.theme.orange>10%'



You get the idea how searching with colors works, I deliberately included my moderately successful results with a very small image library of 800+ images.
So, for now mfind command line interface (CLI) is only available, but I work on some web demo which will focus on
image-handler features, providing full featured image search facility.
More Image Metadata
There are many more image.* metadata to query:
type(icon, illustration, photo etc),size.ratio(4/3, 16/9),pixels(5M),color.type(bw, grayscale, limited, full),- and so forth,
PS: I gonna update this blog post and rerun the lookups with a larger image library (280K images).
MetaFS Archive (marc)
posted 2015/03/26 by rkmWell, there are so many new additions since the last update back in November 2014, let's focus on marc, the tool and archive format which allows you to create, add and extract items from an archive:
% marc cv ../my.marc .
my.marc of the current directory, with verbosity enabled, and saves it one directory above.
All items are saved with full metadata, so one can transfer volumes easily.
Transfer a volume from machine to another via ssh:
% marc cvz - . | (ssh a01.remote.com "cd alpha/; marc cv -")
marc has no z, as the stream identifies itself being compressed.
It also means, using z flag you still use .marc extension, no need to add .gz or so.
For all full documentation on marc, consult the Handbook.
Changelog 0.4.7
posted 2015/03/25 by rkmFirst post covering version 0.4.7, the past 3 months I haven't updated the github repository as so many changes and updates occured:
- many small improvements compared to 0.3.21
- improved stability (but it's still "alpha", consult FAQ too)
- new archiving format: MetaFS Archive (marc), with the tool with the same name
marcworking liketar, including optional built-in compression, to store items with full metadata on any media - fine-grained metadata updates and mapping of keys introduced (see Cookbook)
- comprehensive documentation (apprx. new 120+ "screen" pages): Handbook & massively extended Cookbook
- automatic metadata extraction:
- text: txt (text/plain), pdf, odf (all sub-formats), html (text/html), word (.doc)
- image: anything ImageMagick handles
- video: anything avtool supports (ogv, mp4, m4v, avi, ..)
- audio: anything avtool supports (ogg, mp3, mpg, m4a, ..)
Authors
- rkm: René K. Müller
 MetaFS.org - the metadata file system - Creative Commons CC 3.0 BY SA 2013-2019
MetaFS.org - the metadata file system - Creative Commons CC 3.0 BY SA 2013-2019