Table of Content
1. Introduction

Semantics (from Ancient Greek: semantikos; important) is the study of meaning. It focuses on the relation between signifiers, like words, phrases, signs, and symbols, and what they stand for, their denotation. (Source: Wikipedia: Semantics)
Semantics in is like the 3rd layer in the file system stack, even though it may look trivial, let's make sure what we talk about:
- Data: the actual raw data, various file formats, not necessarly human readable (e.g. compressed)
- Metadata: data about the raw content, data about data, structure data, machine & human readable
- Semantics: interpreted data from the raw data and metadata, usually human readable, preferable machine readable too
The metadata might contain the author, the publisher, the date it was written, released and when it was included in the filesystem.
The semantics is about the actual content, the description of events in 500BC in India as in this example, which might even allow one to conclude the coordinates of the locations, entities like persons, tribes, cultures involved: who, what, when, where.
2. Semantic Feeds
The semantics feeds are coming from various sources from within the framework:
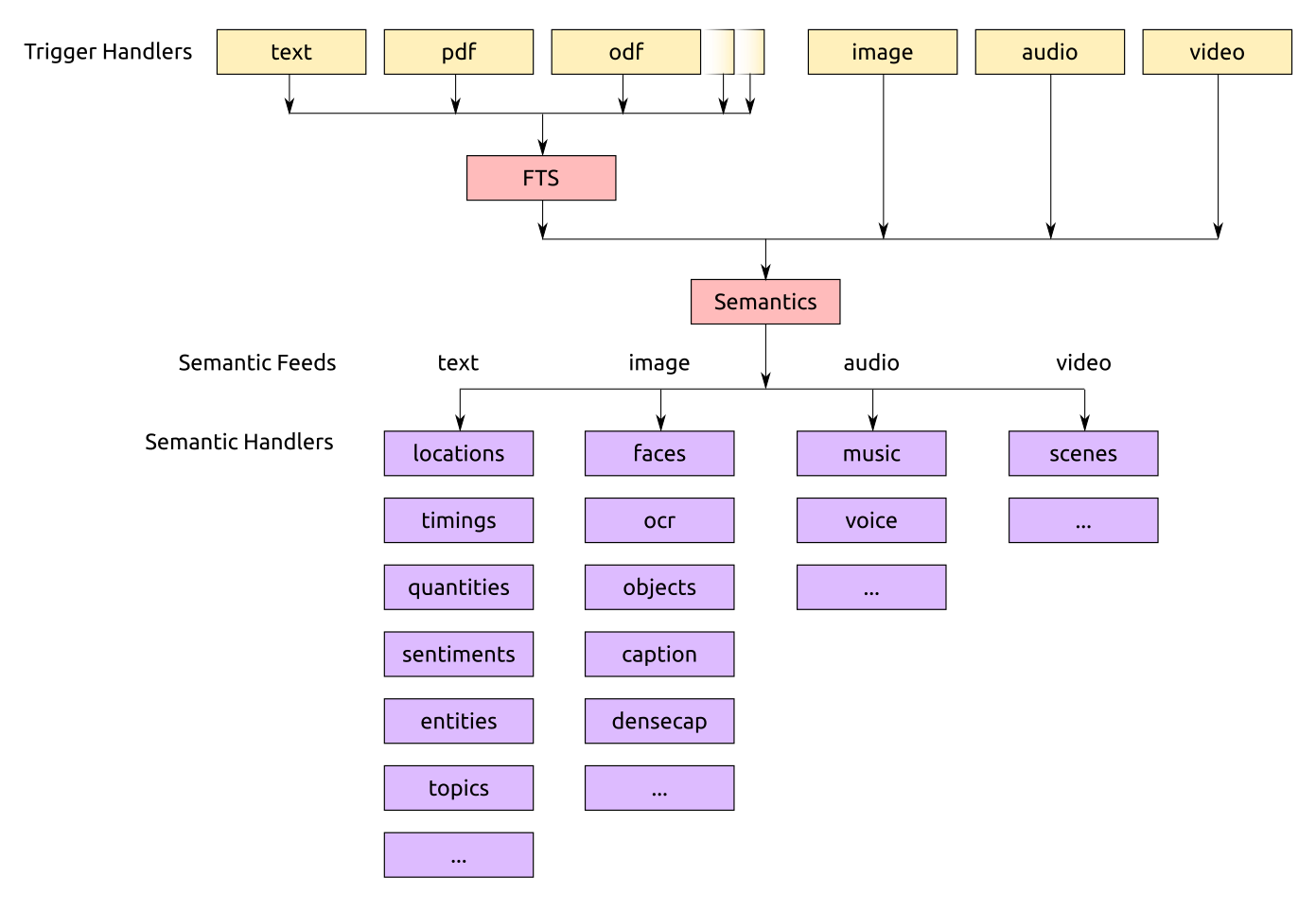
2.1. Text Feeds
A raw skeleton to analyze text content has been included into the full text indexing/search atMetaFS/FTS.pm,
this way even PDFs or ODTs beside of plain texts are analyzed as well: whenever MetaFS::FTS is used
(e.g. via handlers/fts, handlers/odf), MetaFS::Semantics framework is included too.
In semantics/* reside the feed receivers which process the stream of texts from MetaFS::Semantics:
locations: filter out locations usingMetaFS::Geonames, store it insemantics.locationstimings: extract time/date information, and store it insemantics.timingsentities: recognize entities (individuals, organizations, companies), and store it insemantics.entitiesquantities: recognize quantities of any kind, and store it insemantics.quantitiessentiments: determine the sentiments, and store it insemantics.sentimentstopics: determine topics mentioned, and store it insemantics.topicsandtopicsanything: anything else, stores it insemantics.misc.*- ...
conf/semantics.conf (uncomment lines to enable the modules):
{
"feeds": {
"text": {
#"locations": { },
#"timings": { }
#"entities": { },
#"quantities": { },
#"sentiments": { },
#"topics": { },
},
"image": {
#"barcode": { },
#"faces": { },
#"ocr": { },
#"caption": { },
#"densecaption": { },
},
"audio": {
#"music": { },
},
"video": { }
}
}
Ideally a text is analyzed semantically in one go, e.g. for persons, dates, locations, and even make a true text analysis, make the content machine readable/understandable: who/what/when/where/ etc - which goes into the direction to make content universally stored, and able to translate into other human languages.
- who & what: entities and objects
- when: time scale
- where: location
- how many: quantities
semantics/locations as mentioned does a basic lookup of locations, uses some heuristics/pattern matching to do so without actual semantic analysis of the entire text.
2.1.1. Locations
By default Geonames, a geographical database, is integrated in , which allows:
- location name to GPS coordinate and
- GPS coordinate to location name
mfind and mls and -g switch, as well the handlers/location and semantics/locations.
2.1.1.1. Location in Images

For now the place with the largest population is considered, if places are found with the same name. Later also some heuristics are included, where an area, like a country, is set to eliminate or reduce the ambiguities.
By default JPEG photos are analyzed by handlers/image and EXIF metadata are read out and mapped to image.EXIF and further the GPS coordinate mapped so spherical nearby sorting is possible.
Coordinates to location mapping might help a human to determine where an item relates to, yet, for the machine the actual coordinates are more useful.
Metadata:
location:body, planetary body, e.g. "Earth", or "Moon" or "Mars".elevation, elevation in meters above sea levellat, latitude in degrees, e.g.47.15261long, longitude in degrees, e.g.8.509180
citycountry, two letter abbreviation of country, e.g. "GB", or "US"
% mls -l 20130914_140844.jpg
20130914_140844.jpg
uid: 1237cc2db15dcb5c5229129110248d86-54510688-b787fe
size: 3,517,355 bytes
mime: image/jpeg
ctime: 2014/10/29 15:23:52.501 (3days 20hrs 19mins 18secs ago)
mtime: 2013/09/14 12:08:16.000 (1yr 1month 17days 23hrs 34mins 54secs ago)
utime: 2014/10/29 15:23:52.671 (3days 20hrs 19mins 17secs ago)
atime: 2014/10/29 15:23:52.671 (3days 20hrs 19mins 17secs ago)
mode: rwxr--r--
hash: f74b72a8cf30087cca26bdacd6d803f884d163930f70f14a6a89c177ae50b18e
image:
EXIF: {
Aperture: 2.7
ApertureValue: 2.6
BitsPerSample: 8
...
GPSAltitude: "477.3 m Above Sea Level"
GPSAltitude1: "477.3 m"
GPSAltitudeRef: "Above Sea Level"
GPSDateStamp: 2013:09:14
GPSDateTime: "2013:09:14 12:08:16Z"
GPSLatitude: "47 deg 9' 9.41" N"
GPSLatitude1: "47 deg 9' 9.41""
GPSLatitudeRef: North
GPSLongitude: "8 deg 30' 33.05" E"
GPSLongitude1: "8 deg 30' 33.05""
GPSLongitudeRef: East
GPSPosition: "47 deg 9' 9.41" N, 8 deg 30' 33.05" E"
GPSProcessingMethod:
GPSTimeStamp: 12:08:16
GPSVersionID: 2.2.0.0
...
}
location:
body: Earth
elevation: 477 m
lat: 47.1526138888889 deg
long: 8.50918055555556 deg
parent: 0
thumb:
height: 375 px
mtime: 2014/10/29 15:23:53.979 (3days 20hrs 19mins 16secs ago)
src: thumb/12/37/cc2db15dcb5c5229129110248d86-54510688-b787fe
width: 500 px
version: 1
mls with the -g switch lookup the Geonames, and shows (but not sets) nearest known location to that GPS coordinate:
% mls -lg 20130914_140844.jpg
20130914_140844.jpg
uid: 1237cc2db15dcb5c5229129110248d86-54510688-b787fe
size: 3,517,355 bytes
mime: image/jpeg
ctime: 2014/10/29 15:23:52.501 (3days 20hrs 19mins 18secs ago)
...
location:
body: Earth
city: Zug
country: CH
elevation: 477 m
lat: 47.1526138888889 deg
long: 8.50918055555556 deg
...
2.1.1.2. Location in Texts
The modulesemantics/locations parses the text and looks up locations.
Status: inmature (alpha)
Languages: any
There are too many false locations found which are also common english terms.
- Geonames.org: cities
- DBpedia.org: geocoords, places and locations
- Wikidata.org: anything with a location
2.1.2. Entities
Determine which individual or person, organization, company, state or country is involved, also known as named entity (NE).
Status: beta
Languages: any[1]
Metadata:
semantics.entities:individual: array of objects each listing individuals, first mention has highest count of mentionorganization: array of object each listing organization, first mention has highest count of mentioncompany: array of objects each listing company, first mention has highest count of mention
text.entities&entities: contains an array with the entities, ordered by count of mention
name: full qualified name, which implies abbreviations are traced down to the full name, e.g. "UN" -> "United Nations")type: one ofindividual,organization,companycount: count of mentionssource: source of the information
2.1.2.1. Individual
Thetype as individual you may encounter additional keys:
birthDatebirthPlacedeathDatedeathPlacedescription: object withlanandvaluecontaining a very brief descriptionsubtype: array of typesgivenName: object withlanandvaluesurName: object withlanandvalue
- USA: Time Top 100 Most Influential People (2011-2015)
- UK: The Independent Top 50 Influential People (2016)
- Global: Top 600 Influential People (of All Time) (2016/04)
- Global: Top 3,000 Musicians (2016/04)
Also, the birthPlace and deathPlace will later reference Wikidata, DBpedia geocoords and Geonames as well, so long/lat can be determined as well.
Example:
{
birthDate: 1910/03/23 12:00:00.000 (106y 0mo 10d 20hr 42m 13s ago)
birthPlace: "Ota, Tokyo"
count: 1
deathDate: 1998/09/06 12:00:00.000 (17y 6mo 27d 20hr 42m 13s ago)
deathPlace: Setagaya
description: {
lan: en
value: "Japanese film director, screenwriter, producer, and editor"
}
givenName: {
lan: en
value: Akira
}
name: "Akira Kurosawa"
subtype: [ "film producer", screenwriter, "film editor" ]
surname: {
lan: en
value: Kurosawa
}
type: individual
}
2.1.2.2. Organization
Thetype as organization, currently about 800 organizations are in the database, e.g. prominent non-profit organizations like Amnesty International, WWF, Oxfam, UCLA, etc
are recognized via their full names and their abbreviations.
Example:
{
abbreviation: UNESCO
count: 1
name: "United Nations Educational, Scientific and Cultural Organization"
source: UN
type: organization
}
2.1.2.3. Company
The type as company you may encounter additional keys which aren't normalized yet, which means, different datasets have overlapping metadata but keys aren't the same yet.
Currently the database consists:
- Global: Fortune 1000 (2012)
- Germany: BaFin ~10,000 registered businesses (2016)
Example:
{
assets: 17.9
continent: "North America"
count: 1
country: "United States"
industry: "Computer Services"
marketValue: 159.7
name: Facebook
profits: 1.5
rank: 510
sales: 7.9000048828125
sector: "Information Technology"
source: "Fortune Global 1000 (2012)"
type: company
year: 2012
}
2.1.3. Timings
Determine which time scale is involved, from actual dates and timing, to time ranges.

semantics/timings and enabled in conf/semantics.conf:
{
"feeds": {
"text": {
#"locations": { },
"timings": { }
#"entities": { },
#"quantities": { },
#"sentiments": { },
#"topics": { },
}
}
}
Status: beta
Languages: english, german, french, italian
Metadata:
semantics.timings, is an array [] which contains individual timings:day, month, year, actual numeric datetime, determined time in UNIX epoch (seconds since 1970/01/01, negative number earlier time)margin, in secondsquality, quality of correctness: 0 = uncertain, 1 = reliable, >1 very certain
% more timings.txt
05/13/05, 2006/03/22, April 5th 2014 - and May 6th 1896,
1st June 1900; and it happened in December of 1760.
10AD or 15 A.D. and 20 B.C., 10,000 BC mammoths roamed on Earth.
% mls -l timings.txt
timings.txt
uid: 3fdb1f8bf429b7c393c5657245e070e4-54551ace-955221
size: 175 bytes
mime: text/plain
ctime: 2014/11/01 17:39:26.602 (17hrs 40mins 37secs ago)
mtime: 2014/11/01 19:43:54.029 (15hrs 36mins 9secs ago)
utime: 2014/11/01 19:43:54.029 (15hrs 36mins 9secs ago)
atime: 2014/11/02 11:19:48.137 (15secs ago)
mode: rw-rw-r--
hash: 6d8d68f4b9d993ed9955e53082392536ed9e7994511ecb9d1881673810be68f4
parent: 0
semantics:
timings: [ {
day: 13
margin: 86400
month: 5
quality: 0.11
time: 1115942400
year: 2005
}, {
day: 22
margin: 86400
month: 3
quality: 1.01
time: 1142985600
year: 2006
}, {
day: 5
margin: 86400
month: 4
quality: 1.36
time: 1396656000
year: 2014
}, {
day: 6
margin: 86400
month: 5
quality: 1.57
time: -2324332800
year: 1896
}, {
day: 1
margin: 86400
month: 6
quality: 1.72
time: -2195942400
year: 1900
}, {
margin: 2635200
month: 12
quality: 1.53
time: -6596812800
year: 1760
}, {
margin: 31536000
quality: 1.00
time: -61851600000
year: 10
}, {
margin: 31536000
quality: 1.90
time: -61693833600
year: 15
}, {
margin: 31536000
quality: 2.63
time: -62766748800
year: -19
}, {
margin: 31536000
quality: 3.37
time: -377705116800
year: -9999
} ]
text:
excerpt: "05/13/05, 2006/03/22, April 5th 2014 - and May 6th 1896, 1st June 1900; and it happened in December of 1760. 10AD or 15 A.D. and 20 B.C., 10,000 BC mammoths roamed on Earth."
language: en
lines: 3
uniqueWords: 32
words: 35
version: 1
% mfind semantics.timings.year:2005
semantics.timings.year:
timings.txt
% mfind semantics.timings.year:10000BC mammoths
semantics.timings.year AND fts:
timings.txt
2.1.4. Quantities
Determine any amount of anything.

semantics/quantities and enabled in conf/semantics.conf:
{
"feeds": {
"text": {
#"locations": { },
#"timings": { }
#"entities": { },
"quantities": { },
#"sentiments": { },
#"topics": { },
}
}
}
Status: beta
Languages: english
Metadata:
semantics.quantities, is an array [] which contains individual quantities:quantity, actual amountunit, what unit was recognized (common metric & american unit measurements)kind, if unit wasn't recognized, the kind of quantity is guessed heretype, what kind of number it is, e.g.mass,distanceetc.quality, quality of correctness: 0 = uncertain, 1 = reliable, >1 very certainmargin, is the rangequantity+/-marginpercent: if number was in percent, e.g.25%thenpercent: 25andquantity: 0.25.
% more quantities.txt
One time, or a dozen eggs, it won't matter because it was the first time; and I told you a dozens times, 12 towels.
In the year of 10,000 BC, it was common to collect water from a nearby source.
If you won over 1,000,000,000 dollars you would be considered rich, where just 0.10 USD, or 10 cents would not be much.
How likely is it, when I would write 10,000,000,000,000,000?
And 3,00,00,000 rupees or 3 crores.
And a special case of some sort, 10,000.50 EUR.
I have zero time, or the budget came close to 0.
0 or 0.0, zero or null.
We have 2.5% increase in market share, or full 10 % or 25 percent expansion.
Further, this item is about 10kg or 20 pounds.
10lb is about 5kg or so?
1l is about 3oz, is this right? Two gallons is about 2x 3.51 liter.
About 3 inches up (3.2" to be exact).
% mls -l quantities.txt
quantities.txt
uid: 304e0581e94356dc158c82cd2876e207-54ce76e1-27664a
size: 788 bytes
mime: text/plain
ctime: 2015/02/01 18:56:33.903 (21hrs 4mins 26secs ago)
mtime: 2015/02/02 15:40:22.506 (20mins 37secs ago)
utime: 2015/02/02 15:40:22.506 (20mins 37secs ago)
atime: 2015/02/02 16:00:40.439 (19secs ago)
mode: rw-rw-r--
hash: 284477b4a2c0aa96f088b606b70a3a5665fab6a4d5c3e18563ac467a372766f5
parent: 0
semantics:
quantities: [ {
quality: 1
quantity: 1
type: multiplier
unit: time
}, {
kind: egg
quality: 1
quantity: 12
type: named
}, {
margin: 12
quality: 0.9
quantity: 36
type: multiplier
unit: time
}, {
kind: towel
quality: 1
quantity: 12
}, {
kind: BC
quality: 1
quantity: 10000
}, {
quality: 0.6561
quantity: 1000000000
type: currency
unit: USD
}, {
quality: 1
quantity: 0.1
type: currency
unit: USD
}, {
kind: cent
quality: 1
quantity: 10
}, {
quality: 0.531441
quantity: 10000000000000000
}, {
kind: rupee
quality: 1
quantity: 30000000
}, {
kind: crore
quality: 1
quantity: 3
}, {
quality: 0.81
quantity: 10000.5
type: currency
unit: EUR
}, {
quality: 1
quantity: 0
type: multiplier
unit: time
}, {
quality: 1
quantity: 0
type: integer
}, {
quality: 1
quantity: 0
type: integer
}, {
quality: 1
quantity: 0
type: float
}, {
quality: 1
quantity: 0
type: named
}, {
quality: 1
quantity: 0
type: float
}, {
quality: 1
quantity: 0
type: named
}, {
kind: increase
percent: 2.5
quality: 1
quantity: 0.025
type: percent
}, {
percent: 10
quality: 1
quantity: 0.1
type: percent
}, {
kind: percent
percent: 25
quality: 1
quantity: 0.25
type: percent
}, {
quality: 0.833333333333333
quantity: 10
type: mass
unit: kilogram
}, {
quality: 1
quantity: 20
type: mass
unit: pound
}, {
quality: 0.833333333333333
quantity: 10
type: mass
unit: pound
}, {
quality: 0.833333333333333
quantity: 5
type: mass
unit: kilogram
}, {
quality: 1
quantity: 1
type: volume
unit: liter
}, {
quality: 0.833333333333333
quantity: 3
type: mass
unit: ounce
}, {
quality: 1
quantity: 2
type: volume
unit: gallon
}, {
quality: 1
quantity: 2
type: multiplier
unit: time
}, {
quality: 1
quantity: 3.51
type: volume
unit: liter
}, {
quality: 1
quantity: 3
type: distance
unit: inch
}, {
quality: 1
quantity: 3.2
type: distance
unit: inch
}, {
quality: 1
quantity: 20
type: currency
unit: USD
}, {
quality: 0.75
quantity: 21
type: currency
unit: USD
}, {
quality: 1
quantity: 22
type: currency
unit: USD
}, {
quality: 1
quantity: 99
type: currency
unit: EUR
} ]
text:
excerpt: "One time, or a dozen eggs, it won't matter because it was the first time; and I told you a dozens times, 12 towels. In th
e year of 10,000 BC, it was common to collect water from a nearby source. If you won over 1,000,000,000 dollars you would be considered ric
h, where just 0.10 USD, or 10 cents would not be much. How likely is it, when I would write 10,000,000,000,000,000? And 3,00,00,000 rupees
or 3 crores. And a special case of some sort, 10,000.50 EUR. I have zero time, or the budget came close to 0. 0 o"
language: en
lines: 14
uniqueWords: 98
words: 161
version: 1
2.1.5. Sentiments
Determine the sentiment of the text: positive, negative, neutral or none.
The current implementation uses a lexicon of words and counts their occurency which only allows very basic conclusion of the sentiment, e.g. sarcasm or jokes are not picked up, but indication of negations are picked up.
semantics/sentiments and enabled in conf/semantics.conf:
{
"feeds": {
"text": {
#"locations": { },
#"timings": { }
#"entities": { },
#"quantities": { },
"sentiments": { },
#"topics": { },
}
}
}
Status: beta[1]
Languages: english, german
Metadata:
semantics.sentiments:polarity:conclusion:positive,negative,neutral(too close to call) or nonesummary: in percentage (-100% .. 100%), computational summary
positive: in percentage (0 .. 100%), positive attitude expressed,positive+negative= 100%negative: in percentage (0 .. 100%), negative attitude expressednegation: in percentage (0 .. 100%), reversing meaning of (part of) a sentence with "not" (e.g. english "didn't")inverse: in percentage (0 .. 100%), inverse meaning of a word with absence of something (e.g. english "clueless")intellectual: in percentage (0 .. 100%), abstract & intellectualanalytical: in percentage (0 .. 100%), objective without personal attachmentemotional: in percentage (0 .. 100%), subjective, personal and emotionalaffirmative: in percentage (0 .. 100%), subjective, motivational, more subtle positivepoetic: in percentage (0 .. 100%), artistic, aiming for transcendenceshallow: in percentage (0 .. 100%), overused term(s), superficialityvulgar: in percentage (0 .. 100%), sub-set of obscenity (e.g. cursing)_quality: in percentage (0 .. 100%), gives an idea of how good the sentiment conclusion is_stats: provides some absolute numbers (not displayed by default, unless-aused withmls) in case you want to calculate your own conclusions_all: total amount of checked words_match: total amount of words which were determined to have sentiments
% mls -a 2600-8.txt
2600-8.txt
title: "War and Peace"
author: "Leo Tolstoy"
uid: cb397d2091006e3fc698a1bf0666d970-54eb5596-f006f5
size: 3,226,653 bytes
mime: text/plain
otime: 1869/06/15 00:00:00.000 (145yrs 11months 2days 20hrs 29mins 59secs ago)
ctime: 2015/02/23 16:30:14.706 (2months 24days 3hrs 59mins 44secs ago)
mtime: 1869/06/15 00:00:00.000 (145yrs 11months 2days 20hrs 29mins 59secs ago)
utime: 2015/02/23 16:34:05.915 (2months 24days 3hrs 55mins 53secs ago)
atime: 2015/02/25 14:05:24.166 (2months 22days 6hrs 24mins 34secs ago)
...
semantics:
...
sentiments: {
_quality: 56.02%
_stats: {
_all: 566033
_match: 31708
affirmative: 2797
analytical: 219
emotional: 5573
intellectual: 1847
negative: 15933
poetic: 676
positive: 15783
shallow: 207
}
affirmative: 72.13%
analytical: 4.04%
emotional: 100.00%
intellectual: 30.18%
negative: 50.24%
poetic: 12.58%
polarity: {
conclusion: neutral
summary: -0.47%
}
positive: 49.76%
shallow: 3.61%
}
text:
author: "Leo Tolstoy"
ctime: 1805/06/15 00:00:00.000 (209yrs 11months 2days 20hrs 22mins 53secs ago)
encoding: ascii
excerpt: "The Project Gutenberg EBook of War and Peace, by Leo Tolstoy This eBook is for the use of anyone anywhere at no cost and with almost no restrictions whatsoever. You may copy it, give it away or re-use it under the terms of the Project Gutenberg License included with this eBook or online at www.gutenberg.org Title: War and Peace Author: Leo Tolstoy Translators: Louise and Aylmer Maude Posting Date: January 10, 2009 [EBook #2600] Last Updated: March 15, 2013 Language: English Character set encoding:"
language: en
lines: 65,008
mtime: 1869/06/15 00:00:00.000 (145yrs 11months 2days 20hrs 22mins 53secs ago)
rtime: 1869/06/15 00:00:00.000 (145yrs 11months 2days 20hrs 22mins 53secs ago)
title: "War and Peace"
uniqueWords: 17,115
words: 555,062
2.1.6. Topics
Determine the topics which are covered in the text.
The current implementation uses a hierarchical lexicon of words and topics, for example:
- science
- physics
- astrophysics
- dark matter
- astrophysics
- physics
- layer: ~60 topics
- layer: 0-10 sub(1)-topics
- layer: 0-3 sub(2)-topics
semantics/topics and enabled in conf/semantics.conf:
{
"feeds": {
"text": {
#"locations": { },
#"timings": { }
#"entities": { },
#"quantities": { },
#"sentiments": { },
"topics": { },
}
}
}
Status: beta[1]
Languages:
- full: english, german
- partial: french, italian, japanese, chinese
Metadata:
semantics.topics:art- ...
love- ...
science- ...
war- ...
zoology
semantics.topics._stats:all: all wordsmatch: words which lead to topic determination(s)
% mls -a 2600-8.txt
2600-8.txt
title: "War and Peace"
...
semantics: {
topics: {
analysis: 0.00210378681626928
animal: 0.104488078541374
art: 0.0406732117812062
authenticity: 0.000701262272089762
commerce: 0.350631136044881
computer: 0.00140252454417952 **) because of the Gutenberg header & footer
data: 0.000701262272089762
economics: 0.768583450210379
education: 0.02945301542777
emotion: 0.76367461430575
entertainment: 0.0238429172510519
family: 0.800841514726508
flora: 0.00841514726507714
food: 0.376577840112202
fruit: 0.00561009817671809
geography: 0.0476858345021038
government: 0.0399719495091164
health: 0.165497896213184
history: 0.103786816269285
industry: 0.000701262272089762
judaism: 0.0091164095371669
jurisdiction: 0.0539971949509116
law: 0.0518934081346424
library: 0.00420757363253857
literature: 0.0722300140252454
love: 0.29523141654979
measurement: 0.0406732117812062
media: 0.0666199158485273
music: 0.0890603085553997
nature: 0.164796633941094
peace: 0.0715287517531557
physics: 0.0119214586255259
politics: 0.398316970546985
psychology: 0.0336605890603086
relationship: 1
religion: 0.240532959326788
restaurant: 0.00140252454417952
science: 0.229312762973352
shelter: 0.255960729312763
spirituality: 0.187938288920056
sport: 0.00210378681626928
time: 0.748948106591865
transportation: 0.0161290322580645
war: 0.192847124824684
...
relationship: 1family: 0.800841514726508economics: 0.768583450210379emotion: 0.76367461430575time: 0.748948106591865politics: 0.398316970546985food: 0.376577840112202commerce: 0.350631136044881love: 0.29523141654979shelter: 0.258765778401122religion: 0.240532959326788science: 0.229312762973352war: 0.192847124824684spirituality: 0.187938288920056health: 0.165497896213184nature: 0.164796633941094animal: 0.104488078541374history: 0.103786816269285
text.topics gets an array of the topics which reach 10% at least:
text
topics: [ relationship, economics, emotion, time, politics, food, commerce, love, shelter, religion, .. ]
2.1.7. Anything (Else)
Determine anything else possible which are covered in the text:
- email addresses (e.g.
[email protected]) - phone numbers (e.g,
(605) 134 124 4565) - URIs/URLs or web links (e.g.
www.test.com,http://www.test.com,ftp://ftp.test.com/dists/) - Internet domain names (e.g.
test.com) - IPv4 addresses (e.g.
192.168.2.1) - IPv4 networks (e.g.
192.168.2.0/24) - IPv6 addresses
semantics/anything and enabled in conf/semantics.conf:
"feeds": {
"text": {
...
"anything": { }.
...
}
}
Status: alpha
Languages: any
Metadata:
semanticsmiscdomain: array with domain namesemail: array with email addressedipv4: array with IPv4 addressesipv4-net: array with IPv4 networksipv6: array with IPv6 addressesphone: array of phone numbersuri: array of URIs/URLs (https://, http://, ftp:// etc)
% cat example.txt
My ip is 192.168.0.2, on the 192.168.0.0/24
2001:e6:8b:7f:9db4:c0dd:559c:1296
A web-site is www.simplydifferently.org and Simplydifferently.org is a domain name.
Link is http://metaqlue.com/docs.html or just metafs.org/docs.html
+22 607 123 4567
+22 6071234567
+226071234567
(302)1234567
(302) 1234567
(302) 123 4567
(0609) 123 4567
Example: Telephone: National (0609) 123 4567
International +22 609 123 4567
E-mail: [email protected]
Web: www.doecorp.com
% mls -l example.txt
...
semantics:
...
misc: {
domain: [ simplydifferently.org ]
email: [ [email protected] ]
ipv4: [ 192.168.0.2 ]
ipv4-net: [ 192.168.0.0/24 ]
ipv6: [ 2001:e6:8b:7f:9db4:c0dd:559c:1296 ]
phone: [ +226071234567, 3021234567, 06091234567, +226091234567 ]
uri: [ http://metafs.org/docs.html, http://metaqlue.com/docs.html,
http://www.doecorp.com, http://www.simplydifferently.org ]
}
...
% mfind semantics.misc.phone:
# lists all phone numbers in all items
2.2. Audio Feeds
In the planning is an audio feed infrastructure, which analyzes the audio stream further:
- auto classify audio content (e.g. music, voice, spoken words, rain, waves, city noise, applause etc):
- music: autodetect music style
- spoken words: voice recognition and transcription and feeding then into Text feed
2.2.1. Music
Analyze audio in regards of music, low-level & high-level conclusions using Essentia.
semantics/music and enabled in conf/semantics.conf:
{
"feeds": {
...
"audio": {
"music": { }
},
...
}
}
Status: alpha
Metadata:
audio.type:voice,musicaudio.subtype: in caseaudio.type=musicthen subtype is set eithervocal,instrumentalaudio.topics: array of topics, whenaudio.type=music, then genres are included e.g.jazz, ordance musicplusmusic, due to mapping copied totopicsaudio.musiccontains low-level conclusions:lowlevel: various bands and their mean, variance, min, max, median, etcrhythmbeats_count: integerbpm: integer (e.g.120)- many more (see example below)
tonalchords_key: chords key (e.g.B)chords_scale: chords scale (e.g.minor)key_key: key key (e.g.A)key_scale: key scale (e.g.minor)- some more (see example below)
semantics.musiccontains high-level conclusions:danceability:value(0..1),all.*,probability(0..1)gender:value(male,female),all.*,probability(0..1)genre_dortmund:value(alternative,blues,electronic,folkcountry,funksoulrnb,jazz,pop,raphiphop,rock),all.*,probability(0..1)genre_electronic:value(ambient,dnb,house,techno,trance),all.*,probability(0..1)genre_rosamerica:value(classic,dance,hiphop,jazz,pop,rhythm,rock,speech),all.*,probability(0..1)genre_tzanetakis:value(blues,classic,country,disco, hiphop,jazz,metal,pop,reggae,rock),all.*,probability` (0..1)genres: array of strings: simplified genres conclusion based ongenre_*mood_acoustic:value(0..1),all.*,probability(0..1)mood_aggressive:value(0..1),all.*,probability(0..1)mood_electronic:value(0..1),all.*,probability(0..1)mood_happy:value(0..1),all.*,probability(0..1)mood_party:value(0..1),all.*,probability(0..1)mood_relaxed:value(0..1),all.*,probability(0..1)mood_sad:value(0..1),all.*,probability(0..1)mood_mirex:value(0..1),all.*,probability(0..1)timbre:value(dark,light),all.*,probability(0..1)tonal_atonal:value(tonal,atonal),all.*,probability(0..1)voice_instrumental:value(voice,instrumental),all.*,probability(0..1)
% mls -l "Steve Reich - Piano Phase (Peter Aidu) CC BY NC ND.mp3"
Steve Reich - Piano Phase (Peter Aidu) CC BY NC ND.mp3
title: "Piano Phase"
author: "Steve Reich"
copyright: http://www.top-40.org
uid: 01d4d8410a6cc78c1093d21934d8b7a8-554f8233-4e7ad1
size: 41,982,080 bytes
mime: audio/mp3
otime: 2015/05/10 16:07:15.553 (10mo 21d 18hr 57m 22s ago)
ctime: 2015/05/10 16:07:15.553 (10mo 21d 18hr 57m 22s ago)
mtime: 2015/05/10 16:07:16.784 (10mo 21d 18hr 57m 21s ago)
utime: 2015/05/10 16:07:16.784 (10mo 21d 18hr 57m 21s ago)
atime: 2016/03/30 13:49:59.912 (21hr 14m 38s ago)
mode: rw-rw-r--
hash: d952b9c13f5ea5817142c3b0a7107a1aaffb3f1f4194e43264f1d8af383ea1e7
audio:
album: "Performed By Peter Aidu"
artist: "Steve Reich"
bitrate: 256 kbps
bits: s16p
channels: 2
codec: mp3
composer: "Steve Reich"
copyright: http://www.top-40.org
date: 2006
duration: 21m 51s 839ms 999us
freq: 44100 Hz
genre: "Top 40"
music: {
lowlevel: {
average_loudness: 0.925695002079
barkbands: {
dmean: [ (27 entries, hidden due verbosity) ]
dmean2: [ (27 entries, hidden due verbosity) ]
dvar: [ (27 entries, hidden due verbosity) ]
dvar2: [ (27 entries, hidden due verbosity) ]
max: [ (27 entries, hidden due verbosity) ]
mean: [ (27 entries, hidden due verbosity) ]
median: [ (27 entries, hidden due verbosity) ]
min: [ (27 entries, hidden due verbosity) ]
var: [ (27 entries, hidden due verbosity) ]
}
barkbands_crest: {
dmean: 2.94369053841
dmean2: 4.46142101288
dvar: 6.5581817627
dvar2: 14.5855989456
max: 26.0690765381
mean: 14.9501657486
median: 14.7574882507
min: 4.22292280197
var: 19.5916576385
}
barkbands_flatness_db: {
dmean: 0.0299068912864
dmean2: 0.0444543585181
dvar: 0.000623150088359
dvar2: 0.00137673341669
max: 0.450355470181
mean: 0.296239674091
median: 0.295395195484
min: 0.0565141253173
var: 0.00178648624569
}
barkbands_kurtosis: {
dmean: 3.5750477314
dmean2: 5.09892034531
dvar: 20.4563789368
dvar2: 44.4730186462
max: 143.617675781
mean: 6.6599316597
median: 4.89509010315
min: -1.71882581711
var: 42.3391227722
}
barkbands_skewness: {
dmean: 0.542728900909
dmean2: 0.763101220131
dvar: 0.239111468196
dvar2: 0.496850669384
max: 10.2441120148
mean: 2.03178358078
median: 1.94568753242
min: -2.18476462364
var: 0.912294447422
}
barkbands_spread: {
dmean: 1.66640841961
dmean2: 2.34865403175
dvar: 2.52173614502
dvar2: 5.1397600174
max: 90.6297073364
mean: 5.89157438278
median: 5.4490275383
min: 0.49585416913
var: 7.96861839294
}
dissonance: {
dmean: 0.0394434668124
dmean2: 0.065661534667
dvar: 0.00100412336178
dvar2: 0.00264997780323
max: 0.500000119209
mean: 0.420009404421
median: 0.425072610378
min: 0.215025812387
var: 0.00195338553749
}
dynamic_complexity: 1.82814645767
erbbands: {
dmean: [ (40 entries, hidden due verbosity) ]
dmean2: [ (40 entries, hidden due verbosity) ]
dvar: [ (40 entries, hidden due verbosity) ]
dvar2: [ (40 entries, hidden due verbosity) ]
max: [ (40 entries, hidden due verbosity) ]
mean: [ (40 entries, hidden due verbosity) ]
median: [ (40 entries, hidden due verbosity) ]
min: [ (40 entries, hidden due verbosity) ]
var: [ (40 entries, hidden due verbosity) ]
}
erbbands_crest: {
dmean: 3.49540495872
dmean2: 5.20434761047
dvar: 9.68736171722
dvar2: 21.1039962769
max: 32.6554107666
mean: 15.2166643143
median: 14.3832149506
min: 2.32455229759
var: 28.3376255035
}
erbbands_flatness_db: {
dmean: 0.0220952890813
dmean2: 0.0323972664773
dvar: 0.000377194897737
dvar2: 0.000836176914163
max: 0.487487435341
mean: 0.347621738911
median: 0.346568644047
min: 0.0317416600883
var: 0.00113889982458
}
erbbands_kurtosis: {
dmean: 1.78288781643
dmean2: 2.61191797256
dvar: 7.15134906769
dvar2: 16.1770362854
max: 52.6374702454
mean: 1.87824308872
median: 0.899592995644
min: -1.59245753288
var: 10.8775672913
}
erbbands_skewness: {
dmean: 0.458157628775
dmean2: 0.629544734955
dvar: 0.186897590756
dvar2: 0.386262387037
max: 6.14682388306
mean: 1.33020722866
median: 1.24992978573
min: -0.936230123043
var: 0.565770804882
}
erbbands_spread: {
dmean: 2.98860120773
dmean2: 4.21634864807
dvar: 7.09555387497
dvar2: 14.7085018158
max: 94.205871582
mean: 14.4037466049
median: 14.113401413
min: 1.25244212151
var: 24.2831325531
}
gfcc: {
cov: [ (13 entries, hidden due verbosity) ]
icov: [ (13 entries, hidden due verbosity) ]
mean: [ (13 entries, hidden due verbosity) ]
}
hfc: {
dmean: 4.67422819138
dmean2: 6.24417066574
dvar: 21.60679245
dvar2: 34.7036552429
max: 63.8779029846
mean: 14.3435297012
median: 12.647851944
min: 1.06481590443e-16
var: 71.4941864014
}
melbands: {
dmean: [ (40 entries, hidden due verbosity) ]
dmean2: [ (40 entries, hidden due verbosity) ]
dvar: [ (40 entries, hidden due verbosity) ]
dvar2: [ (40 entries, hidden due verbosity) ]
max: [ (40 entries, hidden due verbosity) ]
mean: [ (40 entries, hidden due verbosity) ]
median: [ (40 entries, hidden due verbosity) ]
min: [ (40 entries, hidden due verbosity) ]
var: [ (40 entries, hidden due verbosity) ]
}
melbands_crest: {
dmean: 3.42468547821
dmean2: 4.9977645874
dvar: 9.1639623642
dvar2: 19.1654338837
max: 36.6484870911
mean: 18.1512069702
median: 17.8321762085
min: 1.55522847176
var: 30.0810985565
}
melbands_flatness_db: {
dmean: 0.030998038128
dmean2: 0.0437672883272
dvar: 0.000741396099329
dvar2: 0.00153598736506
max: 0.543959259987
mean: 0.346526265144
median: 0.345663249493
min: 0.00225630798377
var: 0.0025197272189
}
melbands_kurtosis: {
dmean: 4.82699251175
dmean2: 6.76445484161
dvar: 31.7788772583
dvar2: 65.9468231201
max: 332.495819092
mean: 11.2524194717
median: 8.68552684784
min: -1.43102526665
var: 87.300819397
}
melbands_skewness: {
dmean: 0.584214389324
dmean2: 0.840184092522
dvar: 0.256059914827
dvar2: 0.531447708607
max: 16.3215503693
mean: 2.37672376633
median: 2.22872877121
min: -1.99499964714
var: 1.07559144497
}
melbands_spread: {
dmean: 2.45078468323
dmean2: 3.47049570084
dvar: 6.84285163879
dvar2: 14.4537353516
max: 172.390197754
mean: 7.95252227783
median: 6.91847801208
min: 0.797653853893
var: 47.1175498962
}
mfcc: {
cov: [ (13 entries, hidden due verbosity) ]
icov: [ (13 entries, hidden due verbosity) ]
mean: [ (13 entries, hidden due verbosity) ]
}
pitch_salience: {
dmean: 0.0818029046059
dmean2: 0.124306641519
dvar: 0.00508857006207
dvar2: 0.0120951142162
max: 0.910317420959
mean: 0.461013376713
median: 0.466842651367
min: 0.111582882702
var: 0.0117951938882
}
silence_rate_20dB: {
dmean: 0
dmean2: 0
dvar: 0
dvar2: 0
max: 1
mean: 1
median: 1
min: 1
var: 0
}
silence_rate_30dB: {
dmean: 0.000141605458339
dmean2: 0.000283215922536
dvar: 0.000141569325933
dvar2: 0.00035387542448
max: 1
mean: 0.999893784523
median: 1
min: 0
var: 0.000106181883893
}
silence_rate_60dB: {
dmean: 0.00814231391996
dmean2: 0.0162849146873
dvar: 0.00807470083237
dvar2: 0.0220325943083
max: 1
mean: 0.0096289999783
median: 0
min: 0
var: 0.00953513197601
}
spectral_centroid: {
dmean: 87.5597839355
dmean2: 119.984115601
dvar: 10239.3818359
dvar2: 17738.5039062
max: 11869.3505859
mean: 716.632751465
median: 667.876708984
min: 368.194824219
var: 239087.765625
}
spectral_complexity: {
dmean: 2.48737049103
dmean2: 3.87276530266
dvar: 4.57307481766
dvar2: 10.4600219727
max: 24
mean: 12.2173423767
median: 12
min: 0
var: 11.9558839798
}
spectral_contrast_coeffs: {
dmean: [ 0.054396186024, 0.056784786284, 0.0553359501064, 0.0487522408366, 0.0386201962829, 0.0356222726405 ]
dmean2: [ 0.0903772115707, 0.0859997868538, 0.0794095993042, 0.0702532380819, 0.0550463050604, 0.0594452433288 ]
dvar: [ 0.0018943491159, 0.00206890888512, 0.00181400275324, 0.00136550655589, 0.000944632804021, 0.000766674871556 ]
dvar2: [ 0.00502015836537, 0.00488488189876, 0.00415096664801, 0.00306652253494, 0.00214447337203, 0.00210365816019 ]
max: [ -0.435881018639, -0.351954758167, -0.491515010595, -0.520375788212, -0.540093421936, -0.583474099636 ]
mean: [ -0.732539534569, -0.623265564442, -0.678845763206, -0.692252933979, -0.672179102898, -0.708545088768 ]
median: [ -0.738857030869, -0.622223973274, -0.671748399734, -0.687526106834, -0.668939590454, -0.705983996391 ]
min: [ -0.975317180157, -0.978323996067, -0.974145889282, -0.97056466341, -0.9664747715, -0.965667009354 ]
var: [ 0.00292662275024, 0.00608438113704, 0.00439775642008, 0.00346492463723, 0.00233397795819, 0.00185355939902 ]
}
spectral_contrast_valleys: {
dmean: [ 0.479829221964, 0.390135318041, 0.496649414301, 0.520079314709, 0.477819919586, 0.519004821777 ]
dmean2: [ 0.814740717411, 0.627313375473, 0.7742228508, 0.831680357456, 0.762820839882, 0.899156212807 ]
dvar: [ 0.135661691427, 0.104765444994, 0.162084922194, 0.188619360328, 0.190813884139, 0.155369132757 ]
dvar2: [ 0.381135702133, 0.257504224777, 0.379043221474, 0.436531692743, 0.437884032726, 0.457125335932 ]
max: [ -6.96531963348, -4.65652084351, -5.95921325684, -7.13980722427, -7.75438404083, -11.7369766235 ]
mean: [ -8.56407260895, -6.31538391113, -7.85677671432, -8.8458070755, -9.71186161041, -13.9126777649 ]
median: [ -8.50623321533, -6.21360683441, -7.88212203979, -8.93719863892, -9.76709938049, -13.8851184845 ]
min: [ -28.0805721283, -28.1592617035, -27.7338962555, -27.6636581421, -27.5679187775, -27.3784599304 ]
var: [ 0.946418642998, 1.22726345062, 1.10144019127, 1.01924014091, 0.970853984356, 0.631978809834 ]
}
spectral_decrease: {
dmean: 2.01943328726e-09
dmean2: 2.69653455121e-09
dvar: 3.95295015001e-18
dvar2: 6.04363219104e-18
max: 1.88535108194e-28
mean: -6.1445368793e-09
median: -5.2166297948e-09
min: -3.00344460413e-08
var: 1.5339245551e-17
}
spectral_energy: {
dmean: 0.00803258176893
dmean2: 0.0107271205634
dvar: 6.25493048574e-05
dvar2: 9.58077362156e-05
max: 0.119014687836
mean: 0.0244918558747
median: 0.0208303369582
min: 9.81100668415e-21
var: 0.000240712222876
}
spectral_energyband_high: {
dmean: 1.14814965855e-05
dmean2: 1.67500456882e-05
dvar: 2.87317031278e-10
dvar2: 6.44342190714e-10
max: 0.000340172147844
mean: 1.76608136826e-05
median: 1.01214191091e-05
min: 7.16081774455e-21
var: 4.49325326946e-10
}
spectral_energyband_low: {
dmean: 0.000159361370606
dmean2: 0.000287003989797
dvar: 3.17806900796e-08
dvar2: 9.42214839483e-08
max: 0.00245738402009
mean: 0.000215709107579
median: 0.00016997687635
min: 1.25786285252e-23
var: 3.04360163739e-08
}
spectral_energyband_middle_high: {
dmean: 0.00127523066476
dmean2: 0.00165204878431
dvar: 1.4424707615e-06
dvar2: 2.40838789978e-06
max: 0.0201237853616
mean: 0.00319125154056
median: 0.00280923349783
min: 1.11460356012e-21
var: 4.47058573627e-06
}
spectral_energyband_middle_low: {
dmean: 0.0073188864626
dmean2: 0.00979659333825
dvar: 5.26634248672e-05
dvar2: 8.06913303677e-05
max: 0.110583037138
mean: 0.0210869759321
median: 0.0174677595496
min: 1.4934325907e-22
var: 0.000210061785765
}
spectral_entropy: {
dmean: 0.290916055441
dmean2: 0.437024384737
dvar: 0.0647541210055
dvar2: 0.148354664445
max: 9.82836818695
mean: 6.13301610947
median: 6.11883163452
min: 4.60126018524
var: 0.163198456168
}
spectral_flux: {
dmean: 0.0266662314534
dmean2: 0.0432589538395
dvar: 0.000586820184253
dvar2: 0.00147169071715
max: 0.216080963612
mean: 0.0615980401635
median: 0.0552456825972
min: 6.46684719663e-11
var: 0.00080350326607
}
spectral_kurtosis: {
dmean: 13.9591932297
dmean2: 24.0816326141
dvar: 120.225746155
dvar2: 334.568847656
max: 111.228759766
mean: 24.7822151184
median: 22.7179946899
min: -1.25464367867
var: 211.891326904
}
spectral_rms: {
dmean: 0.000824577815365
dmean2: 0.00109823490493
dvar: 5.25610857949e-07
dvar2: 8.54494999203e-07
max: 0.0107755232602
mean: 0.00464827241376
median: 0.00450802408159
min: 3.09381860408e-12
var: 2.28780663747e-06
}
spectral_rolloff: {
dmean: 159.041732788
dmean2: 269.232055664
dvar: 51954.5585938
dvar2: 96328.6015625
max: 19896.6796875
mean: 836.68951416
median: 667.529296875
min: 43.06640625
var: 730103.8125
}
spectral_skewness: {
dmean: 0.971424102783
dmean2: 1.66908943653
dvar: 0.566607236862
dvar2: 1.58781993389
max: 7.92422246933
mean: 3.06488585472
median: 2.92034959793
min: -0.0592750497162
var: 1.04196071625
}
spectral_spread: {
dmean: 236038.078125
dmean2: 400208.40625
dvar: 72183259136
dvar2: 172841123840
max: 42763092
mean: 1624062.5
median: 1526979.25
min: 756934.875
var: 3062831775740
}
spectral_strongpeak: {
dmean: 0.54787504673
dmean2: 0.831824302673
dvar: 0.242844969034
dvar2: 0.55290210247
max: 6.88345193863
mean: 1.65031790733
median: 1.556240201
min: 0
var: 0.593433380127
}
zerocrossingrate: {
dmean: 0.00362481945194
dmean2: 0.00421246513724
dvar: 1.45112262544e-05
dvar2: 2.14392402995e-05
max: 0.53369140625
mean: 0.0322238057852
median: 0.0302734375
min: 0.00634765625
var: 0.000495079322718
}
}
metadata: {
audio_properties: {
analysis_sample_rate: 44100
bit_rate: 256000
codec: mp3
downmix: mix
equal_loudness: 0
length: 1311.80004883
lossless: 0
md5_encoded: 9b892a44e939c9eb90f4a9cc1d50ed2d
replay_gain: -9.39375686646
sample_rate: 44100
}
tags: {
album: [ "Performed By Peter Aidu" ]
artist: [ "Steve Reich" ]
composer: [ "Steve Reich" ]
copyright: [ http://www.top-40.org ]
date: [ 2006 ]
file_name: semantics-audio-550.mp3
genre: [ "Top 40" ]
originalartist: [ "Peter Aidu" ]
title: [ "Piano Phase" ]
tracknumber: [ 01 ]
}
version: {
essentia: 2.1-dev
essentia_git_sha: v2.1_beta2-546-g5c457ef
extractor: "music 1.0"
}
}
rhythm: {
beats_count: 2463
beats_loudness: {
dmean: 0.0179563648999
dmean2: 0.0333242341876
dvar: 0.000226015123189
dvar2: 0.00073919724673
max: 0.0945534706116
mean: 0.0379543863237
median: 0.0369717404246
min: 0
var: 0.000345416949131
}
beats_loudness_band_ratio: {
dmean: [ 0.00750549370423, 0.21002805233, 0.22637359798, 0.0720228031278, 0.0283288005739, 0.00163986429106 ]
dmean2: [ 0.0133513770998, 0.379802852869, 0.409733772278, 0.129874393344, 0.0510574877262, 0.00303960777819 ]
dvar: [ 0.000420945638325, 0.0504310056567, 0.0418756566942, 0.00644164951518, 0.000999483396299, 5.21423717146e-05 ]
dvar2: [ 0.000674751412589, 0.140772014856, 0.128064870834, 0.0190104972571, 0.0029909638688, 0.000154868946993 ]
max: [ 0.938217043877, 0.947048425674, 0.972053587437, 0.639287173748, 0.201607108116, 0.248814970255 ]
mean: [ 0.00992429535836, 0.256003320217, 0.593388080597, 0.105982348323, 0.0400565005839, 0.0017563670408 ]
median: [ 0.00638280482963, 0.174540489912, 0.625302791595, 0.0763846412301, 0.0283908136189, 0.00105774798431 ]
min: [ 0, 0, 0, 0, 0, 0 ]
var: [ 0.00088919576956, 0.0660892874002, 0.065583281219, 0.00652189506218, 0.00101367046591, 2.85144360532e-05 ]
}
beats_position: [ (2463 entries, hidden due verbosity) ]
bpm: 103.032539368
bpm_histogram_first_peak_bpm: {
dmean: 0
dmean2: 0
dvar: 0
dvar2: 0
max: 103
mean: 103
median: 103
min: 103
var: 0
}
bpm_histogram_first_peak_spread: {
dmean: 0
dmean2: 0
dvar: 0
dvar2: 0
max: 0.571147561073
mean: 0.571147561073
median: 0.571147561073
min: 0.571147561073
var: 0
}
bpm_histogram_first_peak_weight: {
dmean: 0
dmean2: 0
dvar: 0
dvar2: 0
max: 0.265637695789
mean: 0.265637695789
median: 0.265637695789
min: 0.265637695789
var: 0
}
bpm_histogram_second_peak_bpm: {
dmean: 0
dmean2: 0
dvar: 0
dvar2: 0
max: 136
mean: 136
median: 136
min: 136
var: 0
}
bpm_histogram_second_peak_spread: {
dmean: 0
dmean2: 0
dvar: 0
dvar2: 0
max: 0.475195765495
mean: 0.475195765495
median: 0.475195765495
min: 0.475195765495
var: 0
}
bpm_histogram_second_peak_weight: {
dmean: 0
dmean2: 0
dvar: 0
dvar2: 0
max: 0.16328188777
mean: 0.16328188777
median: 0.16328188777
min: 0.16328188777
var: 0
}
danceability: 1.72440755367
onset_rate: 6.25465488434
}
tonal: {
chords_changes_rate: 0.0762858837843
chords_histogram: [ (24 entries, hidden due verbosity) ]
chords_key: B
chords_number_rate: 0.000283195869997
chords_scale: minor
chords_strength: {
dmean: 0.00910614430904
dmean2: 0.00837888289243
dvar: 0.000121090255561
dvar2: 0.000176163026481
max: 0.620911002159
mean: 0.379478245974
median: 0.378020852804
min: -1
var: 0.00443325703964
}
hpcp: {
dmean: [ (36 entries, hidden due verbosity) ]
dmean2: [ (36 entries, hidden due verbosity) ]
dvar: [ (36 entries, hidden due verbosity) ]
dvar2: [ (36 entries, hidden due verbosity) ]
max: [ (36 entries, hidden due verbosity) ]
mean: [ (36 entries, hidden due verbosity) ]
median: [ (36 entries, hidden due verbosity) ]
min: [ (36 entries, hidden due verbosity) ]
var: [ (36 entries, hidden due verbosity) ]
}
hpcp_entropy: {
dmean: 0.495416849852
dmean2: 0.845125496387
dvar: 0.178825318813
dvar2: 0.442450493574
max: 3.83842778206
mean: 1.44639492035
median: 1.47766041756
min: 0
var: 0.2716819942
}
key_key: A
key_scale: major
key_strength: 0.651561141014
thpcp: [ (36 entries, hidden due verbosity) ]
tuning_diatonic_strength: 0.48633441329
tuning_equal_tempered_deviation: 0.0262556560338
tuning_frequency: 441.272583008
tuning_nontempered_energy_ratio: 0.614290952682
}
}
title: "Piano Phase"
topics: [ "classic music", music ]
track: 1
type: instrumental
parent: 0
semantics:
music: {
danceability: {
all: {
danceable: 0.384699106216
not_danceable: 0.615300893784
}
probability: 0.615300893784
value: not_danceable
}
gender: {
all: {
female: 0.681343138218
male: 0.318656891584
}
probability: 0.681343138218
value: female
}
genre_dortmund: {
all: {
alternative: 1.75088842215e-14
blues: 2.19690717305e-14
electronic: 0.999999761581
folkcountry: 1.99247711663e-08
funksoulrnb: 2.11183390775e-08
jazz: 7.37540517548e-08
pop: 1.54389478979e-08
raphiphop: 2.69289355259e-08
rock: 9.49514031845e-08
}
probability: 0.999999761581
value: electronic
}
genre_electronic: {
all: {
ambient: 0.524040281773
dnb: 0.00544915115461
house: 0.00972663983703
techno: 0.176116213202
trance: 0.284667730331
}
probability: 0.524040281773
value: ambient
}
genre_rosamerica: {
all: {
classic: 0.902020812035
dance: 0.000613401585724
hiphop: 0.00119478185661
jazz: 0.07280382514
pop: 0.00220838258974
rhythm: 0.00480810552835
rock: 0.00106021226384
speech: 0.0152904745191
}
probability: 0.902020812035
value: classic
}
genre_tzanetakis: {
all: {
blues: 1.35028385557e-05
classic: 0.994520246983
country: 3.5524051782e-05
disco: 6.03901316936e-05
hiphop: 4.26378319389e-05
jazz: 0.00414598593488
metal: 0.000469279184472
pop: 7.73572683102e-05
reggae: 0.000606844085269
rock: 2.82329619949e-05
}
probability: 0.994520246983
value: classic
}
genres: [ classic ]
ismir04_rhythm: {
all: {
ChaChaCha: 0.00211339956149
Jive: 1.12965535664e-05
Quickstep: 1.00819661384e-05
Rumba-American: 6.69943765388e-05
Rumba-International: 9.81816083367e-06
Rumba-Misc: 1.71968204086e-05
Samba: 2.17401247937e-05
Tango: 0.00592390680686
VienneseWaltz: 0.991786181927
Waltz: 3.93591981265e-05
}
probability: 0.991786181927
value: VienneseWaltz
}
mood_acoustic: {
all: {
acoustic: 0.939262628555
not_acoustic: 0.0607373453677
}
probability: 0.939262628555
value: acoustic
}
mood_aggressive: {
all: {
aggressive: 0.085307829082
not_aggressive: 0.914692163467
}
probability: 0.914692163467
value: not_aggressive
}
mood_electronic: {
all: {
electronic: 0.973170936108
not_electronic: 0.0268290601671
}
probability: 0.973170936108
value: electronic
}
mood_happy: {
all: {
happy: 0.333162933588
not_happy: 0.66683703661
}
probability: 0.66683703661
value: not_happy
}
mood_party: {
all: {
not_party: 0.995642364025
party: 0.00435766298324
}
probability: 0.995642364025
value: not_party
}
mood_relaxed: {
all: {
not_relaxed: 0.0126085402444
relaxed: 0.987391471863
}
probability: 0.987391471863
value: relaxed
}
mood_sad: {
all: {
not_sad: 0.647789418697
sad: 0.3522105515
}
probability: 0.647789418697
value: not_sad
}
moods_mirex: {
all: {
Cluster1: 0.0772224962711
Cluster2: 0.0444036349654
Cluster3: 0.227748185396
Cluster4: 0.0306321550161
Cluster5: 0.619993507862
}
probability: 0.619993507862
value: Cluster5
}
timbre: {
all: {
bright: 0.904057860374
dark: 0.095942132175
}
probability: 0.904057860374
value: bright
}
tonal_atonal: {
all: {
atonal: 0.0636984109879
tonal: 0.936301589012
}
probability: 0.936301589012
value: tonal
}
voice_instrumental: {
all: {
instrumental: 1
voice: 3.94596092184e-14
}
probability: 1
value: instrumental
}
}
thumb:
height: 250 px
mime: image/x-png
mtime: 2016/03/28 09:09:24.496 (3d 1hr 55m 13s ago)
src: thumb/01/d4/d8410a6cc78c1093d21934d8b7a8-554f8233-4e7ad1
type: waveform
width: 500 px
topics: [ "classic music", music ]
Query examples:
% mfind topics=jazz
... anything related to jazz: text, image, audio etc
% mfind audio.music.rhythm.bpm=~120
... just music with about 120bpm (beats per minute)
% mfind semantics.music.gender=male
... music with male voice
% mfind semantics.music.genres=disco
... just disco for The Martian
2.3. Image Feeds
Image items are passed on to various handlers, such as:
ocr: converting scanned pages into text againbarcode: decode barcodesfaces: face detection (what is a face) & recognition (who is it), optionally incl. age & genderobjects: detect objects in generalcaption: image caption, overall and detailed captiondensecap: dense or details captions of parts of the imageplaces: recognize places and determine location thereby
2.3.1. OCR
Theocr handler (OCR = Optical Character Recognition) scans black/white images
and saves the recognized text as <name>.txt as sub-item and turns the image as node (indicated by + trailer).
In combination of the explode trigger for the pdf-handler you can achieve this:
% mtrigger pdf explode scan.pdf
(after a while all pages are extracted as JPGs, and ocr handler called as part of the chain)
% cd scan.pdf+/
% ls
000000.jpg 000000.jpg+/ 000001.jpg 000001.jpg+/
000002.jpg 000002.jpg+/ 000003.jpg 000003.jpg+/
...
% cd 000000.jpg+/
% ls
000000.jpg.txt
% less 000000.jpg.txt
Once upon the time was a ...
Status: beta[1]
Language: english
Metadata:
type:node
In order to recognize scanned pages image.theme.white + image.theme.gray > 95% is required, otherwise ocr-handler will not process the image.
2.3.2. Faces

cd into the image itself and discover all the faces as individual files; performed via dlib/OpenFace.
Status: coming soon
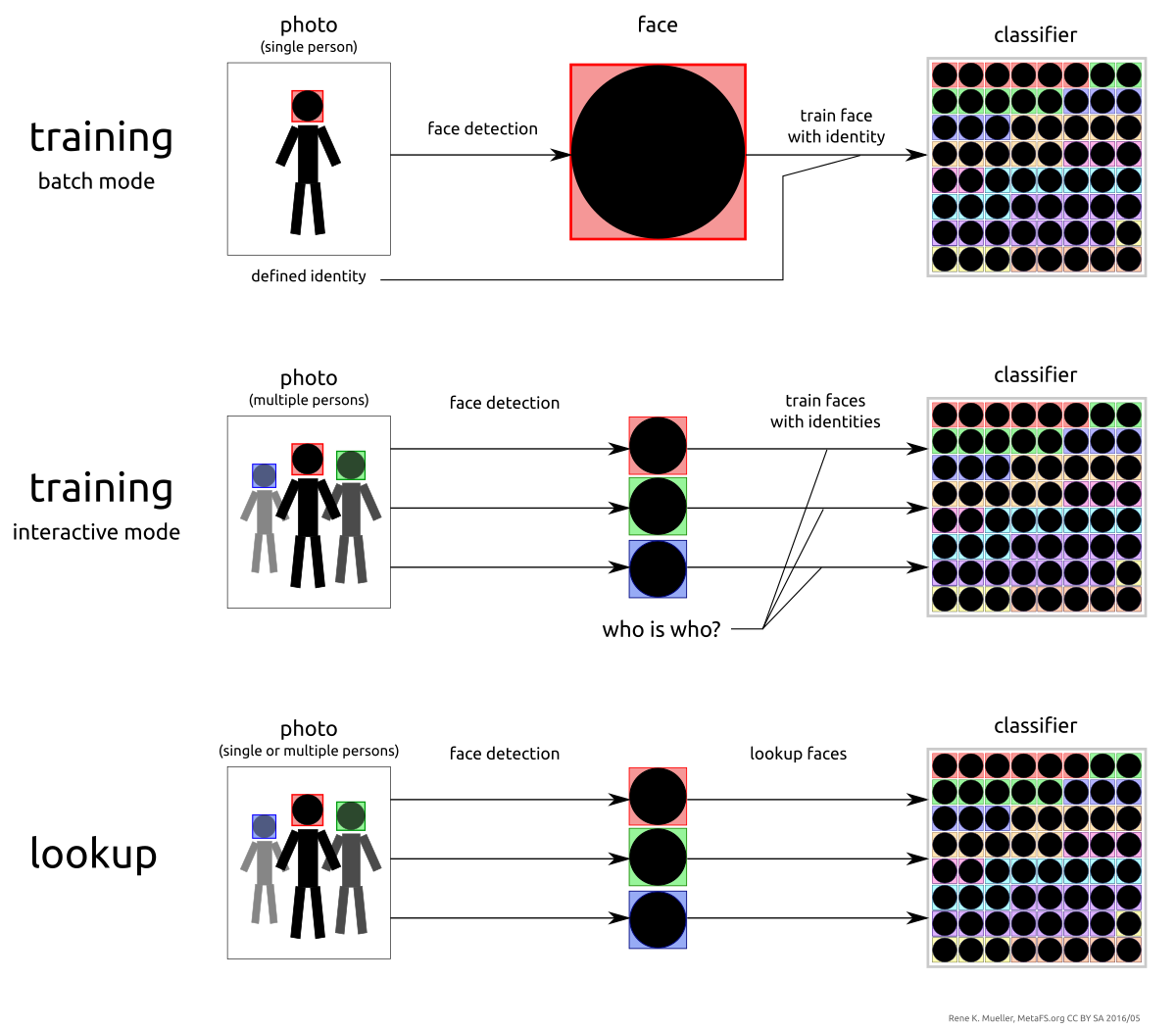
semantics.entities.individual: array of individuals whose faces are detected and recognized
2.3.3. Objects
Recognize objects in an image of any kind you trained beforehand with a set.
Status: coming soon
2.3.4. ImageTags
Automatic image tagging based image content with Darknet/Image-Net.
Status: coming soon
Metadata:
image.tags: array of english terms as recognized in the image
% mls -l test.jpg
...
image:
tags: [ "chain mail", breastplate, cuirass, poncho, "fur coat", cardigan ]
..
...
2.3.5. Caption
Automatic caption images based on image content with NeuralTalk2.
Status: coming soon
Metadata:
image.caption: single english sentence describing overall image (no recognition of actual individuals of who-is-who)
% mls -l test.jpg
...
image:
caption: "a sheep standing on a lush green hillside"
..
...
2.4. Video Feeds
Videos will be broken down into scenes, hence, cuts are detected in audio or video - then the numbered scenes are fed to- video handlers, e.g. analysis of dynamics (e.g. is camera steady or moving)
- video broken down into
- images (frame rate depends on the dynamic of the scene)
- audio
- and automatically feed into the image and audio feeds.
2.4.1. Scenes
scenes determines scenes (cut position & duration), and extracts frames and concludes image tags and caption:
Status: beta
Metadata:
semantics.scenesis an array of objectsframe: frame number starting with 0time: time of scence cut, starting with 0duration: duration of scene, starting withtimetags: scene tags (frame of middle of scene)captionscene caption (frame of middle of scene)
semantics.video.tags&video.tags: summarized tags from all scenes sorted by occurances
frame and time, starting with 0:00:00 as first cut and the duration of the scene.
The image autocaption is done in the middle of a scene (time + duration / 2).
Coming soon:
- voice recognition of speech
- face recognition of faces
% mls -la "Impressive Brazilian Commercial - TV Ad-xeTinkrVXBY.mkv"
{
name: "Impressive Brazilian Commercial - TV Ad-xeTinkrVXBY.mkv"
uid: 92fb43e4faddd82f391a674c66228a03-57303d47-62bd36
size: 10,781,817 bytes
mime: video/x-matroska
otime: 2014/03/10 01:21:28.000 (2y 2mo 1d 7h 12m 14s ago)
ctime: 2016/05/09 07:33:27.000 (1h 0m 15s ago)
mtime: 2014/03/10 01:21:28.000 (2y 2mo 1d 7h 12m 14s ago)
utime: 2016/05/09 07:33:27.545 (1h 0m 15s ago)
atime: 2014/03/10 01:21:28.000 (2y 2mo 1d 7h 12m 14s ago)
hash: ff6f2683125076ec978a2bf38883e5e488d324753f342874830e7053f388838c
parent: 0
...
audio: {
bits: fltp
channels: 2
codec: vorbis
duration: 55s 0ms 0us
freq: 44,100 Hz
}
semantics: {
video: {
scenes: [
{
caption: "a bird is standing on a rock in the desert"
duration: 6.043610
frame: 0
tags: [
lakeside
valley
"worm fence"
cliff
alp
"stone wall"
seashore
volcano
sandbar
promontory
]
time: 0
}
{
caption: "a view of a mountain range from a forest"
duration: 5.835210
frame: 145
tags: [
cliff
promontory
megalith
]
time: 6.043610
}
{
caption: "a view of a lake with a mountain in the background"
duration: 2.167364
frame: 285
tags: [
cliff
valley
alp
dam
lakeside
castle
promontory
megalith
seashore
pier
]
time: 11.878820
}
{
caption: "a group of people riding bikes down a street"
duration: 35.803181
frame: 337
tags: [
accordion
"steel drum"
golfcart
"folding chair"
restaurant
"military uniform"
library
turnstile
unicycle
drum
]
time: 14.046184
}
{
caption: "a picture of a UNK UNK in the sky"
duration: 5.043289
frame: 1,196
tags: [
notebook
"digital clock"
laptop
binder
screen
"computer keyboard"
"space bar"
stopwatch
modem
"web site"
]
time: 49.849366
}
]
tags: [
promontory
cliff
megalith
valley
alp
lakeside
seashore
"computer keyboard"
"military uniform"
laptop
stopwatch
"folding chair"
accordion
library
"space bar"
"steel drum"
volcano
"digital clock"
pier
binder
castle
restaurant
sandbar
dam
turnstile
drum
screen
"stone wall"
modem
notebook
unicycle
"web site"
"worm fence"
golfcart
]
}
}
...
video: {
width: 1,280 px
height: 720 px
codec: h264
duration: 55s 0ms 0us
tags: [
...
]
}
}
3. Next Steps
Integrate dictionary to check if we have a sentence with valid (english|german|french...) words, to conclude better the words if they are persons, locations etc.- Webster Dictionary and Wiktionary.org
- DBpedia.org integration (under way since 0.6.0), using geocoords and persons.
- Wikidata.org integration (under way since 0.6.1), using for auto translate and term classifications.
Typical applications:
- news articles, describing actual events - automatic classification to which category and significance to certain topics and focus, timely importance (e.g. warnings of severe weather conditions is highly timely related, after 1-2 days the information becomes irrelevant)
- historical texts, describing actual events - automatic create timeline and geographical distribution
- philosophical / spiritual texts, explaining concepts and perspective - relating philosophical concepts to each other, who introduced which concepts when
4. See Also
- Datahub.io - classified datasets
- AlchemyAPI.com - semantic extraction as service
- Import.io - harvest structured data from web-sites
- Wordnet.Princeton.edu
- Yago-Knowledge.org
5. Updates
Significant updates of this document:- 2016/12/08:
anything(else) handler documented (rkm) - 2016/05/09
scenesvideo handler documented (rkm) - 2016/05/04: more information on
faces,caption,imagetags(rkm) - 2016/03/31:
entitiesandmusicdetailed description, with examples (rkm) - 2015/12/03:
topics,timingsupdated with new language support (french, italian, japanese, chinese) (rkm) - 2015/11/01:
ocr-handler mentioned and briefly explained (rkm) - 2015/09/22: Semantic feed illustration added, clarification on audio and image semantic handlers (rkm)
- 2015/05/17:
sentimentsdocumented (rkm) - 2015/02/08:
quantitiesandtimingsdocumented (rkm)
- rkm: René K. Müller
 MetaFS.org - the metadata file system - Creative Commons CC 3.0 BY SA 2013-2019
MetaFS.org - the metadata file system - Creative Commons CC 3.0 BY SA 2013-2019