Table of Content
- 1. Handlers
- 1.1. Triggers
- 1.1.1. System Triggers
- 1.1.2. Non-Item Triggers
- 1.1.3. Item Triggers
- 1.1.3.1. open & close
- 1.1.3.2. create / change
- 1.1.3.3. update
- 1.1.3.4. delete / undelete / purge
- 1.1.3.5. mkdir
- 1.1.3.6. meta
- 1.1.3.7. import
- 1.1.3.8. export
- 1.1.4. Custom Triggers
- 1.2. Writing Handlers
- 1.3. Connect Handlers
- 1.4. Handler Execution
- 1.5. Dedicated Handler Configuration
- 1.6. Trigger: fsinfo
- 1.7. Trigger: fsck
- 1.8. Trigger: format
- 2. Web GUI
- 3. Query & Aggregation Framework
- 4. Query
- 5. Aggregation Pipeline
- 6. Updates
is expandable by programmers to
- support additional file formats:
- make preview thumbnail
- extract metadata
- extend overall functionality
- e.g. snapshots, journaling, low-level syncing
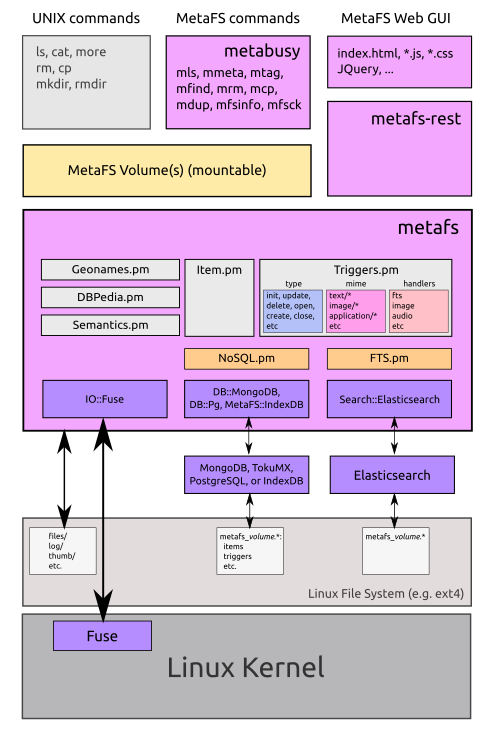
1. Handlers
If you like to support a file format in order to create a preview thumbnail and extract metadata, you write a new handler of that particular file type as revealed via the mime and/or the file extension.[1]
1.1. Triggers
In order to write new or change existing handlers, let's look how handlers are triggered:
1.1.1. System Triggers
Following triggers are predefined in :
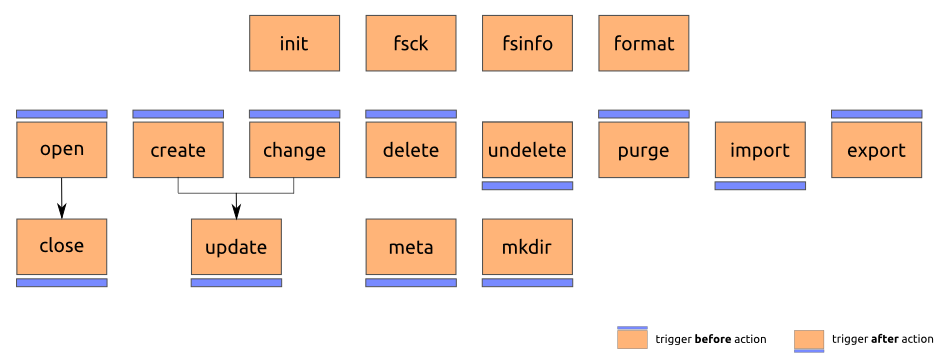
Non-Item Triggers
init: initialization of volume at the moment of mountingfsck:mfsckormetabusy fsckcalledfsinfo:mfsinfoormetabusy fsinfocalledformat:metabusy formatcalled
open/close: opening an item for reading, closing it again (no change of content)create & change: create or change an item (altering content)update: end of change or updatedelete/undelete/purge: delete, undelete, or purge entirelymeta: metadata was alteredmkdir: creating new directoryimport/exportfrom or to a volume (e.g. viamarcarchiving)
1.1.2. Non-Item Triggers
1.1.2.1. init
This trigger is good to use in an handler in order to initialize local data.- Input:
$arg->{type} - Output: none
1.1.2.2. fsck
File-system check trigger is called whenmfsck or metabusy fsck is called; whatever your handler does, if there are consistancy checking possible, please perform it and report it.
- Input:
$arg->{type} - Output: structured data
1.1.3. Item Triggers
Following triggers are predefined in for items:
1.1.3.1. open & close
Theopen trigger indicates, an item is about to be open for reading, no alteration is intendent.
The close trigger indicates, an item has been read but not altered.
- Input:
$arg->{uid},$arg->{type} - Output: none
1.1.3.2. create / change
Thecreate trigger indicates an new item is about to be created, the UID is known, the content isn't known yet.
The change trigger indicates an existing item is about to be changed, the content isn't known yet.
- Input:
$arg->{uid},$arg->{type} - Output: none
1.1.3.3. update
Theupdate trigger indicates an items content was changed or updated, the content is finalized.
- Input:
$arg->{uid},$arg->{type} - Output: none
1.1.3.4. delete / undelete / purge
Thedelete trigger indicates the item is about to be deleted, yet, if the "trash" in metafs.conf is enabled (status: 'on'), then it will still reside in the trash until actually purged.
% rm AA.txt
% mrm AA.txt
The undelete trigger indicates an item formerly resided in the trash and it put back into the live set of items, it can be treated alike update trigger.
% mrm -u AA.txt
The purge trigger inicates an item is actually discharged or purged entirely.
% mrm -p
- Input:
$arg->{uid},$arg->{type} - Output: none
1.1.3.5. mkdir
Themkdir trigger is very UNIX specific, and means a new folder was created, the item doesn't references any content but just a folder item.
- Input:
$arg->{uid},$arg->{type} - Output: none
1.1.3.6. meta
Themeta trigger indicates that metadata of an item was altered, e.g. either by user or another handler.
- Input:
$arg->{uid},$arg->{type},arg->{keys} - Output: none
arg->{keys} is reference to an array which contains all the keys in dot-notion which are altered (changed or deleted), e.g. [ 'name', 'image.width', 'image.height' ].
Caution: if you process meta event, be aware not to call meta() again (on specific keys), if you do review your design or void trigger call via meta($uid,{...},{trigger=>0}), otherwise you create a trigger loop.
1.1.4. Custom Triggers
You can invent your own trigger, please keep lowercase and non-special character notion, e.g. [a-z_0-9] and avoid spaces and '.', and define the trigger in metafs.conf so it can be received by your own handler.
- Input:
$arg->{uid},$arg->{type} - Output: none
handlers/snapshot which uses mksnap custom trigger for its own purpose.
1.2. Writing Handlers
Writing custom handlers is one of the features of .
There is a template handlers/template which helps you to start to code your own handler:
#!/usr/bin/perl
# -- Template
# written by YOUR NAME
#
# Description:
# DESCRIBE WHAT IT DOES
#
# History:
# YYYY/MM/DD: 0.0.1: first version, minimal functionality
my $NAME = 'template'; # -- CHANGE IT
if($0=~/\/$NAME$/) { # -- when testing stand-alone
while($#ARGV>=0) {
my($k,$v) = (shift(@ARGV), shift(@ARGV));
$arg->{$k} = $v;
}
}
main($arg);
# Global variables:
# $conf: contains structured configuration variables (from conf/metafs.conf and all other conf/*), e.g. $conf->{myhandler}->{...} <= conf/myhandler.conf (JSON)
# $db: current MongoDB connection of the default volume
# $fs: current filesystem information
sub main {
my($arg) = @_;
if($conf->{verbose}) {
print "$NAME started:\n";
foreach (sort keys %$arg) {
print "\t$_: $arg->{$_}\n";
}
}
my $uid = $arg->{uid};
if($arg->{type}eq'init') {
} elsif($arg->{type}eq'fsck') {
return 0; # -- return amount of errors
} elsif($arg->{type}eq'fsinfo') {
my $i;
# $i->{info} = "SOMETHING INTERESTING";
return $i;
} elsif($arg->{type}eq'create') {
} elsif($arg->{type}eq'change') {
} elsif($arg->{type}eq'update') {
} elsif($arg->{type}eq'delete') {
} elsif($arg->{type}eq'undelete') {
} elsif($arg->{type}eq'purge') { # -- clean up all files you created in this handler
} elsif($arg->{type}eq'open') {
} elsif($arg->{type}eq'close') {
} elsif($arg->{type}eq'mkdir') {
} elsif($arg->{type}eq'meta') {
}
}
Following global variables are available:
$confcontains all configurations, e.g. also your own$conf->{myhandler}->etc. if you define it either inconf/metafs.conforconf/myhandler.conf.$dbcontains the current MongoDB / TokuMX db connection, volume specific[1]$fscontains the filesystem specific information (mfsinfo)
$fs->{path},
e.g. /var/lib/metafs/volume/alpha for a volume named "alpha"),
because absolute paths in the metadata make it impossible to rename volumes or copy,
or have them somewhere else than the default /var/lib/metafs/volumes.
Best study the existing handlers as stored in /var/lib/metafs/handlers/, given is installed at the default path.
1.3. Connect Handlers
Connect handlers to trigger events and optionally also to specific MIME types inmetafs.conf:
...
"image": {
"triggers": {
# -- items/file and often mime related triggers
"update": { "mime": [ "image/*", "application/pdf" ], "priority": 6, "nice": 10 },
"delete": { "mime": [ "image/*", "application/pdf" ], "priority": 6, "nice": 10 }
}
},
"video": {
"triggers": {
"update": { "mime": [ "application/ogg", "video/*" ], "priority": 6, "nice": 10 },
"delete": { "mime": [ "application/ogg", "video/*" ], "priority": 6, "nice": 10 }
}
},
"audio": {
"triggers": {
"update": { "mime": "audio/*", "priority": 6 }
}
},
...
Hint: Whenever you edit metafs.conf, it will be considered at the next trigger event.
1.4. Handler Execution
There are 3 modes of handler execution: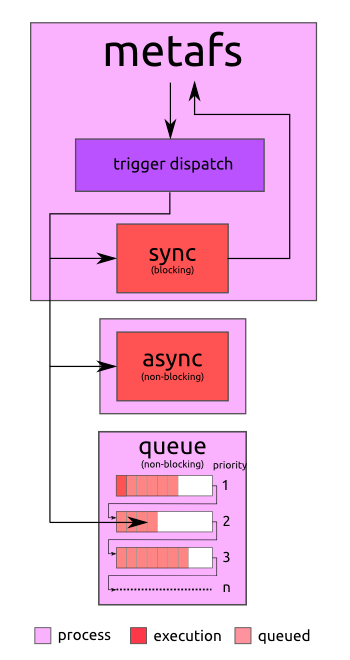
sync: synchronous, be aware: a handler might block the fs operationasync: asynchronous, a separate process (fork) is started, be aware: it might create a lot of processes and cause overheadqueue: this is default, the execution will be queued and processed asynchronous but just in one process
...
"hash": {
"triggers": {
"update": { "exec": "sync" },
"fsck": { }
}
},
"something": {
"triggers": {
"update: { "exec": "async" }
}
},
"image": {
"triggers": {
"update": {
"mime": [ "image/*", "application/pdf" ],
"priority": 2,
"exec": "queue"
},
"delete": {
"mime": [ "image/*", "application/pdf" ],
"priority": 2,
"exec": "queue"
}
}
},
...
By default as mentioned, all handlers are queue executed (there is no requirement for "exec": "queue"), this is the most light approach.
1.4.1. Queued Triggers
In case of queue you can define individually:priority: by default it's 1, e.g. to set priority 3, all tasks in queue 1 and 2 are executed before tasks with priority 3.nice: by default it's 5 (or whatever is defined for triggers { nice: x, list: [ ] }), you can define a nice level for each individual trigger
asyncshould be avoided, as it creates a separate process at each use, and ifsyncis used, it should be fast and 100% reliable (no complex tasks) which would stall the entire file system or worse, take it down.
1.5. Dedicated Handler Configuration
In conf/metafs.conf you can define your own trigger (e.g. "myhandler": { }), yet handler specific settings you can place to conf/myhandler.conf which are mapped to $conf->{myhandler}->{etc}.
Example conf/myhandler.conf:
{
"type": "mytype"
"list": [ 1, 2, 3 ],
"object": {
"sub1": "me"
},
"types": {
"myhandler": {
"name": "string",
"mytime": "date",
"duration": "time",
"distance": "number"
}
},
"units": {
"myhandler": {
"distance": "m"
}
}
}
and so $conf->{myhandler}->{type} is set, @{$conf->{myhandler}->{list}} and $conf->{myhandler}->{object}->{sub1}, and can be referenced in your handler code.
You optionally can define types and units which are specially treated as they are merged to $conf->{types} and $conf->{units}:
typesdefines the type of data (string,number,date,time, etc), and are important in conjunction withmfindandmmetaunitsdefines the units of data, e.g.'m'for meter, or'deg'for degrees
myhandler-handler may set metadata with the prefix myhandler. for sake of consistency:
myhandler.name(type: string as defined inconf/myhandler.conf)myhandler.mytime(type: date)myhandler.duration(type: time)
mmeta:
% mmeta --myhandler.mytime=2015/06 --myhandler.duration=109 BB.txt
myhandler.mytime = 2015/06/15 12:00:00.000 (5months 4days 13hrs 1m 54secs ahead)
myhandler.duration = 1min 39secs
2015/06 is parsed as date, and properly converted into UNIX epoch.
% mls -l BB.txt
...
myhandler: {
mytime: 2015/06/15 12:00:00.000 (5months 4days 13hrs 1min 38secs ahead)
duration: 1min 39secs
distance: 1,500 m
}
...
1.6. Trigger: fsinfo
Collect some data within your handler, and store it in$i->{key} = $data, preferably something human readable.
1.7. Trigger: fsck
Perform your integrity checks, and count the errors - return the integer number of errors. Only output to stdout if there is something relevant; avoid to be too verbose, rather be silent unless there is a problem to notify the user about.
If a task takes long time, you may use a function of dispProgress($title,$count,$max), where as $count: 0..$max, and $max - please make sure $count does not go over $max, but reaches $max.
my $max = 1024+48; # -- calculate the max
for(my $i=0; $i<=$max; $i++) {
# doing something here
dispProgress("\tperforming something",$i,$max);
}
print "\n";
which gives then the user some feedback, see handlers/hash and the section of fsck in there.
2. Web GUI
(coming soon)
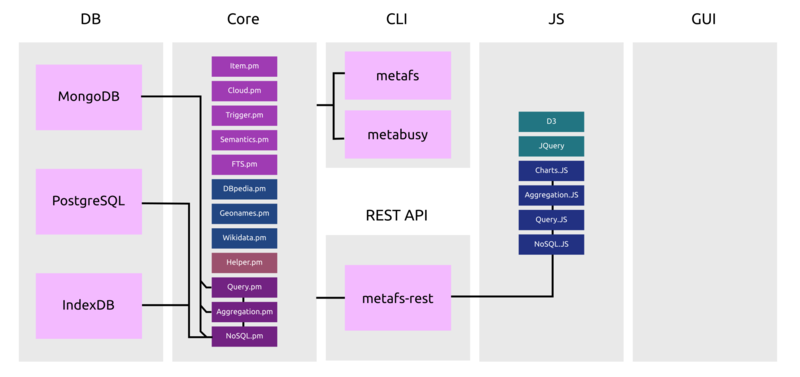
2.1. MetaFS REST
MetaFS REST provides a layer of functionality to the core, it does not access the FUSE mounted disk, but the volume direct (Item.pm, Trigger.pm, NoSQL.pm etc).
3. Query & Aggregation Framework
The MongoDB Query Language and MongoDB Aggregation Pipeline compatible functionality is available within the framework:- in the core (Perl): Query.pm & Aggregation.pm, and
- also GUI level (JavaScript): Query.js & Aggregation.js
3.1. Query
Query is an object-based data structure (recursive key/value) which represents are query:{
"name": "test"
}
name string equal test, or a more complex query
{
"$and": [
{
"name": {
"$regex": "test",
"$options": "i"
}
},
{
"image.width": {
"$gt": 1000
}
}
]
}
/test/i regular expression match plus image.width greater than 1000.
3.2. Aggregation
Aggregation is in this context the query and processing of data before the client of the database receives its result, e.g. to match/query specifics and then process them further, e.g. group results, then pass the results to the db client.[
{
'$match': { // stage 1: perform query (match)
'parent': '1234'
}
},
{
'$project': { // stage 2: project (not really required in this example)
'tags': 1 // only carry tags further
},
},
{
'$unwind': '$tags' // stage 3: explode or unwind array tags
},
{
'$group': { // stage 4: group tags, and count occurance
'_id': '$tags',
'count': {
'$sum': 1
}
}
}
{
'$sort': { // stage 5: nicely sort in descending order
'count': -1
}
}
]
Results
[
{
'_id': 'sun',
'count': 100
},
{
'_id': 'moon',
'count': 63
},
{
'_id': 'mars',
'count': 14
},
]
4. Query
A query is described as an object data structure (recursive key/value), the simplest query is{ key: value }, such as { name: "test" }.
Additionally more operations are possible which replace the value in { key: value }:
4.1. Operations
| Function | Aggregate.pm | Aggregate.js | Operand |
| $eq | ✔ | ✔ | literal e.g. a: { '$eq': 100 } or a: { '$eq': 'test' }, or simply a: 'test' |
| $gt | ✔ | ✔ | literal e.g. a: { '$gt': 100 } |
| $gte | ✔ | ✔ | literal e.g. a: { '$gte': 120 } |
| $lt | ✔ | ✔ | literal e.g. a: { '$lt': 100 } |
| $lte | ✔ | ✔ | literal e.g. a: { '$lte': 100 } |
| $ne | ✔ | ✔ | literal e.g. a: { '$ne': 'here' } |
| $in | |||
| $nin | |||
| $or | ✔ | ✔ | array of operations e.g. '$or': [ ... ] |
| $and | ✔ | ✔ | array of operations e.g. '$and': [ ... ] |
| $not | ✔ | ✔ | object with operation(s) e.g. a: { '$not': { ... } } |
| $nor | ✔ | ✔ | array of operations e.g. '$nor': [ ... ] |
| $exists | ✔ | ✔ | literal, 0 = does not exist, 1 = does exist e.g. a: { '$exists': 1 } |
| $type | |||
| $mod | |||
| $regex | ✔ | ✔ | e.g. a: { '$regexp': 'test', '$options': 'i' } |
| $text | |||
| $where | |||
| $geoWithin | |||
| $geoIntersects | |||
| $near | |||
| $nearSphere | |||
| $all | |||
| $elemMatch | |||
| $size | |||
| $bitsAllSet | |||
| $bitsAnySet | |||
| $bitsAllClear | |||
| $bitsAnyClear | |||
| $comment | |||
| $elemMatch | |||
| $meta | |||
| $slice |
Every query must be an object ({ .. }).
4.1.1. Code Examples
Perl (Server Side)use MetaFS::Query;
my $db = { db => "metafs_alpha", col => "items" };
# or
my @db = (
{ name => "something", type => "A" },
{ name => "something else", type => "B" },
);
my $r = MetaFS::Query::query($db || \@db,{
name => 'something'
});
# -- $r is reference to an array of results
JavaScript (GUI side)
<script src="MetaFS/Query.js"></script>
<script>
var db = { db: "metafs_alpha", col: "items" };
// or
var db = [
{ name: "something", type: "A" },
{ name: "something else", type: "B" }
];
var r = MetaFS.Query.query(db,{
name: "something"
});
// -- r is an array of results
</script>
5. Aggregation Pipeline
The aggregation pipeline is an array of stages:
[ <stage1>, <stage2>, ... ]
whereas each stage is an object (recursive key/value) by itself.
5.1. Stage Operations
| Function | Aggregate.pm | Aggregate.js | Operand |
| $project | ✔ | ✔ | object (e.g. { '$project': { ... } }) |
| $match | ✔ | ✔ | Query object (e.g. { '$match': { ... } }) |
| $redact | |||
| $limit | ✔ | ✔ | literal (e.g. { '$limit': 100 }) |
| $skip | ✔ | ✔ | literal (e.g. { '$skip': 10 }) |
| $unwind | ✔ | ✔ | literal (e.g. { '$unwind': 'tags' }) |
| $group | ✔ | ✔ | object (e.g. { '$group': { ... } }) |
| $sample | ✔ | ✔ | object (e.g. { '$sample': { size: 10 } }) |
| $sort | ✔ | ✔ | object (e.g. { '$sort': { name: 1 } }) |
| $geoNear | |||
| $lookup | |||
| $out | |||
| $indexStats |
5.1.1. Code Examples
Perl (Server Side)
use MetaFS::Query;
my $db = { db => "metafs_alpha", col => "items" };
# or
my @db = (
{ name => "something", type => "A" },
{ name => "something else", type => "B" },
);
my $r = MetaFS::Aggregation::aggregation($db || \@db,[
{ '$project' => { name => 1, type => 1 } }
]);
# -- $r is reference to an array of results
JavaScript (GUI side)
<script src="MetaFS/Aggregation.js"></script>
<script>
var db = { db: "metafs_alpha", col: "items" };
// or
var db = [
{ name: "something", type: "A" },
{ name: "something else", type: "B" }
];
var r = MetaFS.Aggregation.aggregation(db,[
{ '$project': { name: 1, type: 1 } }
]);
// -- r is an array of results
</script>
If MongoDB is the backend (core) the aggregation is passed directly in that case be aware which version of MongoDB (3.2 or later recommended) you run so all aggregation expression features are supported, or if PostgreSQL or other backend then the aggregation is applied after the first query or $match.
Recommendation: In order to take advantage of the aggregation use $match as the first stage, then regardless of backend your aggregation
will perform fast. If the first aggregation stage is not a $match-stage, for non-MongoDB aggregation all entries are retrieved and in memory aggregated which
poses an immense memory demand for large deployments with large sets of items/files.
5.1.2. Project
$project stage is for projecting or filtering keys:
key:valueorexpressionvalue: 0 (disregard) or 1 (regard)expression: evaluate the expression
{
'$project': {
a: 1, # -- regard key "a"
b: {
'$cmp': [
'$b', 10
]
},
c: {
'$lt': [
'$z.date', 100
]
}
}
}
5.1.3. Match
$match is the query operation as useable in the multi-stage aggregation pipeline:
{
'$match': {
'a': {
'$lt': 100,
},
'b': {
'$gt': 10,
}
}
}
Note: multiple keys in $match the order of execution is not defined. If order is important, use $and: [ <query1>, <query2>, ... ]
5.1.4. Group
$group is grouping results of previous matches and aggregation. You must use _id as main group identifier, all additional keys follow:
{
'$group': {
'_id': '$name', // value is an expression therefore '$' ahead is required of keys
'some': '$time', // dito
'some2': {
'$lt': [ // returns true(1) or false(0)
'$time', 200
]
},
...
}
}
5.2. Expression
5.2.1. Boolean/Logical Operators
| Function | Aggregate.pm | Aggregate.js | Operand |
| $and | ✔ | ✔ | array of expressions |
| $or | ✔ | ✔ | array of expressions |
| $not | ✔ | ✔ | array[1] of expression |
Examples:
{ '$and': [ { '$gt': [ '$a', 50 ] }, { '$lt': [ '$a', 100 ] } ] }
{ '$or': [ { '$gt': [ '$a', 100 }, { '$lt': [ '$a', 50 } ] }
{ '$not': [ { '$lt': [ '$a', 100 ] } ] }
5.2.2. Set Operators
| Function | Aggregate.pm | Aggregate.js | Operand |
| $setEquals | |||
| $setIntersection | |||
| $setUnion | |||
| $setDifference | |||
| $setIsSubset | |||
| $anyElementTrue | |||
| $allElementsTrue |
5.2.3. Comparison Operators
| Function | Aggregate.pm | Aggregate.js | Operand | Result |
| $cmp | ✔ | ✔ | array[2] of expressions | -1, 0 or 1 |
| $eq | ✔ | ✔ | array[2] of expressions | true, false or undefined |
| $gt | ✔ | ✔ | array[2] of expressions | true, false or undefined |
| $gte | ✔ | ✔ | array[2] of expressions | true, false or undefined |
| $lt | ✔ | ✔ | array[2] of expressions | true, false or undefined |
| $lte | ✔ | ✔ | array[2] of expressions | true, false or undefined |
| $ne | ✔ | ✔ | array[2] of expressions | true, false or undefined |
Examples:
{ result: { '$cmp': [ '$name', "test" ] } }
{ result: { '$eq': [ '$name', "test" ] } }
{ result: { '$lt': [ '$line', 50 ] } }
5.2.4. Arithmetic Operators
| Function | Aggregate.pm | Aggregate.js | Operand |
| $abs 3.2 | ✔ | ✔ | literal (e.g. { '$abs': '$a' }) |
| $add | ✔ | ✔ | array of expressions (e.g. { '$add': [ 1, '$z', { ... } ] }) |
| $ceil 3.2 | ✔ | ✔ | literal (e.g. { '$ceil': '$a' } }) |
| $divide | ✔ | ✔ | array[2] of expressions (e.g. { '$divide': [ '$a', 10 ] }) |
| $exp 3.2 | ✔ | ✔ | literal (e.g. { '$exp': '$a' }) |
| $floor 3.2 | ✔ | ✔ | literal (e.g. { '$floor': '$a' }) |
| $ln 3.2 | ✔ | ✔ | literal (e.g. { '$ln': '$a' }) |
| $log 3.2 | ✔ | ✔ | array[2] of expressions (e.g. { '$log': [ '$a', 3 ] }) |
| $log10 3.2 | ✔ | ✔ | literal (e.g. { '$log10': '$a' } }) |
| $mod | ✔ | ✔ | array[2] of expressions, (e.g. { '$mod': [ '$a', 10 ] }) |
| $multiply | ✔ | ✔ | array of expressions (e.g. { '$multiply': [ '$a', 10, '$z' ] }) |
| $pow 3.2 | ✔ | ✔ | array[2] of expressions (e.g. { '$pow': [ '$a', 2 ] }) |
| $sqrt 3.2 | ✔ | ✔ | literal (e.g. { '$sqrt': '$a' } }) |
| $subtract | ✔ | ✔ | array[2] of expressions, (e.g. { '$subtract': [ '$a', 10 ] }) |
| $trunc 3.2 |
3.2: MongoDB 3.2 compatible
5.2.5. String Operators
| Function | Aggregate.pm | Aggregate.js | Operand |
| $concat 2.4 | ✔ | ✔ | array of expressions e.g. { '$concat': [ 'Hello', ' ', 'World:', '$name' ] } |
| $substr | ✔ | ✔ | array[3] of expressions: string, pos and length, e.g. { '$substr': [ '$name', 2, 5 ] } |
| $toLower | ✔ | ✔ | literal e.g. { '$toLower': '$name' } |
| $toUpper | ✔ | ✔ | literal e.g. { '$toUpper': '$name' } |
| $strcasecmp |
5.2.6. Array Operators
| Function | Aggregate.pm | Aggregate.js | Operand |
| $arrayElemAt 3.2 | |||
| $concatArrays 3.2 | |||
| $filter 3.2 | |||
| $isArray 3.2 | |||
| $size 2.6 | |||
| $slice 3.2 |
5.2.9. Date Operators
| Function | Aggregate.pm | Aggregate.js | Operand |
| $dayOfYear | |||
| $dayOfMonth | |||
| $dayOfWeek | |||
| $year | |||
| $month | |||
| $week | |||
| $hour | |||
| $minute | |||
| $second | |||
| $millisecond | |||
| $dateToString 3.0 |
5.2.10. Conditional Operators
| Function | Aggregate.pm | Aggregate.js | Operand |
| $cond | ✔ | array[3] of expressions: condition-expression, true-action, false-action, e.g. '$x': { '$cond': [ { '$gt': [ '$x', 100 ] }, 100, 0 ] } | |
| $cond 2.6 | object with 3 expressions, e.g. '$x': { '$cond': { if: { '$gt': [ '$x', 100 ] }, 'then': 10, 'else': 0 } } | ||
| $ifNull | ✔ | array[2] of 2 expressions: condition expression, replacement-if-null; if expression is not null then original value of the key reference is taken, e.g. '$a': { '$ifNull': [ '$b', 'empty' ] } |
6. Updates
Significant updates of this document:- 2016/11/18: 0.7.6: covering
MetaFS/Query.[pm,js]andMetaFS/Aggregation.[pm,js]functionality, current state; Query: ~95%, Aggregation: 75% (rkm) - 2016/10/24: 0.7.5:
handlers-section ofmetafs.confupdated (newtriggerssub structure) (rkm) - 2015/09/12: 0.5.1: first version, with handlers & triggers explained (rkm)
- rkm: René K. Müller
 MetaFS.org - the metadata file system - Creative Commons CC 3.0 BY SA 2013-2019
MetaFS.org - the metadata file system - Creative Commons CC 3.0 BY SA 2013-2019