Table of Content
1. Introduction
MetaFS::IndexDB or IndexDB for short, is a hybrid of an embeddable and client/server NoSQL (schema-free) database which indexes all document content by default, aimed to fulfill the needs of :
There is a 3 layered reference for a document:

- Database (defined as string)
- Collection (defined as string)
- Document (defined as JSON object with
uidas main identifier, globally unique), supporting following types:- string (e.g.
"test") - number (e.g.
12or0.5e6) - array (ordered) (e.g.
[ 12, "test" ]) - object (unordered key/value pairs) (e.g.
{ "size": 12, "name": "test" })
- string (e.g.
- all key/value recursively are indexed by default for providing fast search/find for values (equality, inequality/range)
- low memory footprint is maintained so it can scale based on diskspace instead of memory usage
2. CRUD
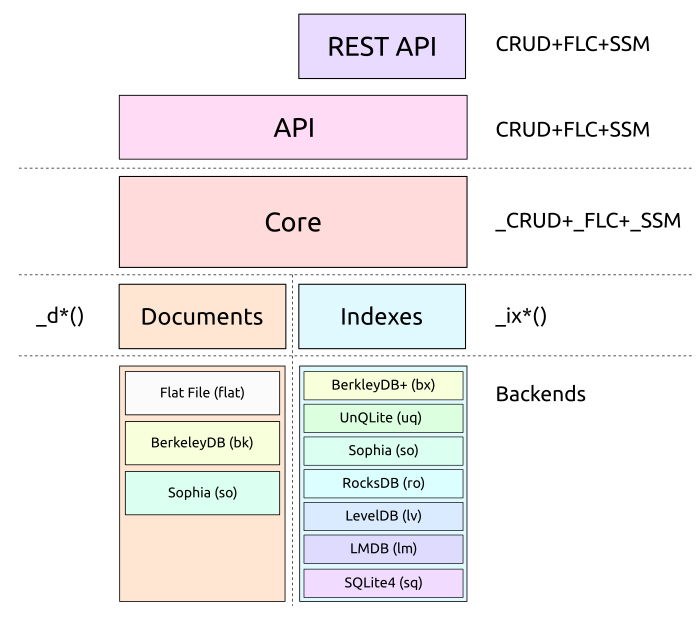
- Perl API (embedded, single user)
- REST API (multi-user)
3. Data Structure
Let's explain the overall data structure of IndexDB with an example where the database name would be'myset', and the collection name 'items', having 3 small documents:
myset.items:
{
"name" : "AA.txt",
"size" : 12,
"uid" : "61b078f21f16641567a84f1343f04956-551783dc-cfcdef"
},
{
"name" : "BB.txt",
"size" : 182,
"uid" : "b32184727775c4c8ed457fa535a86a99-554c7e46-fdc210"
},
{
"name" : "CC.txt",
"size" : 23,
"uid" : "94fd0c3fdd3ed0cf4bbcbb3a5f2cd773-55177848-cf2ed4"
}
which results in following two inverted indexes:
name index (alphanumerical sorted):
| key | value |
AA.txt | 61b078f21f16641567a84f1343f04956-551783dc-cfcdef |
BB.txt | b32184727775c4c8ed457fa535a86a99-554c7e46-fdc210 |
CC.txt | 94fd0c3fdd3ed0cf4bbcbb3a5f2cd773-55177848-cf2ed4 |
size index (numerical sorted):
| key | value |
12 | 61b078f21f16641567a84f1343f04956-551783dc-cfcdef |
23 | 94fd0c3fdd3ed0cf4bbcbb3a5f2cd773-55177848-cf2ed4 |
182 | b32184727775c4c8ed457fa535a86a99-554c7e46-fdc210 |
In real world application a wide variety of documents lead easily to 2000+ keys to be indexed.
4. API
4.1. Init
$ix = new IndexDB({ .. });
host: server (default: none = direct access)port: port of remote access (default:9138)autoConnect: try remote (default:1), if fails, gracefully fallback on localautoType: auto type keys based on first use (number vs string), (default: 1)root: root of db (default:/var/lib/indexdb)maxKeyLength: max length of a key (default:512)maxIndexDepth: max depth of a key (default:32)maxIndexArrayLength: max array length to index (default:1024)syncTimeOut: sync after x seconds (default:30)ixStore: index backend ('',bx(default),uq,so,ro,lm,lv)docStore: document backend (undef, '' orflat(default),bk,pg,so)docType: serializing (json(default),frth)docCompress: document compress ('' (default),sn)sync:0= async (find, list, stats),1= sync (one command at a time)
my $ixdb = new IndexDB({
host => '192.168.1.2',
...
});
Abbreviations:
ixStore:bk: BerkeleyDB 2.0+ (only used as reference), B-treebx: BerkeleyDB 2.0+ extended (better distribution of duplicates, faster delete of dups), B-treepg: PostgreSQL 9.4+, B-treeuq: UnQLite, LSM-tree/B-treeso: Sophia, LSM-treelm: LMDB, B-treesq: SQLite4, LSM-treero: RocksDB, LSM-treelv: LevelDB, LSM-tree
docStore:flat(default)bkpgso
docCompress:
4.1.1. Backends
Several document backends (docStore) are available:
| name | state | functionality | comments | rating |
| flat (default) | mature | CRUD | + reliable, easy to recover | ★★★☆☆ |
| bk | mature | CRUD | - easy to corrupt, expensive to recover | ★☆☆☆☆ |
| pg | infant | CRUD | + reliable, but indexing limits queries (implies ixStore: pg) | ★★☆☆☆ |
| so | infant | CRUD | + fast - memory intensive M(n) | ★☆☆☆☆ |
Several index backends (ixStore) are available:
| name | state | functionality | comments | rating |
| bk | mature | CRUD, find(match, regex, inequality, sort, skip, limit) | + low memory usage - slow delete of dups (do not use in production, only as reference) | ★★☆☆☆ |
| bx (default) | mature | CRUD, find(match, regex, inequality, sort, skip, limit) | + low memory usage + fast delete of dups | ★★★★☆ |
| pg | infant | CRUD, find(match) | + metadata & index together, - in-place update not yet (9.5 perhaps) - not certain if it will be continued, as pg backend optionally is partially also in metafs itself | ★★☆☆☆ |
| uq | infant | CRUD, find(match, regex) | - memory usage significant (surprise) | ★☆☆☆☆ |
| so | moderate | CRUD, find(match, regex) | - no dups natively supported (adding trailer to keys), fast delete of dups then - not so stable yet | ★★★★☆ |
| ro | infant | CRUD, find(match, regex) | + low memory usage - no dups natively supported (adding trailler to keys) - dedicated value sorting does not work yet | ★★☆☆☆ |
| lv | infant | CRUD | - too slow, requires more fine-tuning | ★☆☆☆☆ |
| sq | infant | - | coming soon | |
| lm | infant | - | coming soon |
4.2. Create
$s = $ixdb->create($db,$c,$d)
$db= database (e.g."myset")$c= collection (e.g."items")$d= document, if$d->{uid}is not set, one is created$s != 0=> error
$ixdb->create("myset","items",{
name => "AA.txt",
size => 12
});
which will create a document like this:
{
"name" : "AA.txt",
"size" : 12,
"uid" : "61b078f21f16641567a84f1343f04956-551783dc-cfcdef"
}
4.3. Read
$e = $ixdb->read($db,$c,$d)
$db= database$c= collection$d= document, must have$d->{uid}set$e= JSON object of the docoument
4.4. Update
$s = $ixdb->update($db,$c,$d,$opts)
$db= database$c= collection$d= document, must have$d->{uid}set, along other keys which are updated/set$opts= options (optional)clear: 1, delete existing & set newset: 1, set datamerge: 1 (default), merge all keys recursively
$s!= 0 => error
4.4.1. Update Methods
3 methods are available for updating: merge (default), set and clear:

The 3 methods can be looked in regards of destructiveness of existing data:
merge(default): non destructive, merges strictly and overwrites existing keys if neccessaryset: partially destructive, makes sure other keys not defined in set update are dischargedclear: highly destructive, all is discharged only new update is stored
delete in next section.
Example:
my(@e) = $ixdb->find("myset","items",{name=>"AA.txt"},{limit=>1});
my $a = $e[0];
$ixdb->update("myset","items",{
uid => $a->{uid}, # -- uid must be set
name => "BB.txt");
});
4.5. Delete
$s = $ixdb->delete($db,$c,$d)
$db= database$c= collection (optional)$d= document (optional), if set it must have$d->{uid}set too- a) if
$dbpresent, delete collections - b) if
$db&$cpresent, delete all items in collection - c) if
$db&$c&$dpresent: if uid is only set then delete entire entry, otherwise delete individual keys
- a) if
$s!= 0 => error
$ixdb->delete("myset","items",{uid=>$id}); # -- delete entire item
$ixdb->delete("myset","items",{uid=>$id,a=>1,b=>1}); # -- delete keys a & b of item referenced by $id
4.6. Find
@r = $ixdb->find($db,$c,$q,$opts,$f)
$cu = $ixdb->find($db,$c,$q,{cursor=>1})
$db= database$c= collection$q= query object- MongoDB alike query object:
- exact match:
{ 'name': 'AA1.txt' } - regex:
{ key: { '$regex': 'AA', '$options': 'i' } } - exists:
{ key: { '$exists': 1 } } - distinct:
{ key: { '$distinct': 1 } } - (in)equalities:
{ key: { '$lt': 200 } }$lt$lte$gt$gte$eq$ne
- exact match:
- MongoDB alike query object:
$opts= options (optional)uidOnly:1, do not read entire metadata, only uid (and matching key)limit:n, limit n results (disregarded when$fis set)skip:n, skip n results (disregarded when$fis set)sort: { key =>dir}, whereas dir -1 (descending) or 1 (ascending, default), (disregarded when$fis set), also key must be the same key which is looked for (single key), multiple key match (e.g. AND) sorting not yet availableOR:1, consider all keys in query object logical OR (otherwise logically AND)cursor:1, request a cursor for findNext()
$f= function to be called (optional) if$fis not present, all results are in@r, where each item is an object with matching key/value, plus uid, e.g.{'name':'AA1.txt','uid':'.....'}
Retrieve results in one go:
my(@e) = $ixdb->find("myset","items",{name=>{'$exists'=>1}},{skip=>10,limit=>100});
$db->find("myset","items",{name=>{'$exists'=>1}},{skip=>10,limit=>100},sub {
my($e) = @_;
...
});
my $c = $ixdb->find("myset","items",{name=>{'$exists'=>1}},
{skip=>10,limit=>100,cursor=>1});
Note: Preferably use cursor for results which could be huge (which will use up server memory), and grab the results with findNext() as presented next:
4.7. FindNext
$e = $ixdb->findNext($cu);
findNext() is used in conjunction with find() where a cursor is requested:
Example:
my $c = $ixdb->find("myset","items",{name=>"AA.txt"},{cursor=>1});
while(my $e = $ixdb->findNext($c)) {
...
}
4.8. List
@r = $ixdb->list($db,$c,$k,$f)
$db= database (optional)$c= collection (optional)$k= key (optional)$f= function to be called (optional)- a) if no argument is present, list all databases
- b) if
$dbpresent, list collections - c) if
$db&$cpresent, list items { ... }, preferably use$ffor callback - d) if
$db&$c&$kpresent, list keys { key: '...', 'uid': '.....' }
4.9. Count
$n = $ixdb->count($db,$c,$k)
$db= database (optional)$c= collection (optional)$k= key (optional)- a) if no argument is present, count of all databases
- b) if
$dbpresent, count collections of database - c) if
$db&$cpresent, count items of that collection - d) if
$db&$c&$kpresent, count different values of that key
$nreports count
4.10. Size
$n = $ixdb->size($db,$c,$k)
$db= database (optional)$c= collection (optional)$k= key (optional)- a) if no argument is present, size of all databases
- b) if
$dbpresent, size of all collections of database - c) if
$db&$cpresent, size of all items of that collection - d) if
$db&$c&$kpresent, size of index of that key
$nreports in bytes
4.11. Keys
$k = $ixdb->keys($db,$c)
$db= database$c= collection$kreference to an array listing all keys in dot-notion
{
[
"atime", "author", "ctime", "hash", "image.average.a", "image.average.h", ...
"title", "type", "utime", "uid", "utime"
]
}
4.12. Stats
$i = $ixdb->stats($db,$c,$k)
$db= database (optional)$c= collection (optional)$k= key (optional)- a) if no argument is present, stats of all databases
- b) if
$dbpresent, stats of all collections of database - c) if
$db&$cpresent, stats of all items of that collection - d) if
$db&$c&$kpresent, stats of index of that key
$ireports a structure like:
{
"conf" : {
"autoConnect" : 1,
"backend" : {
"bk" : {
"cache" : 20000000,
"levels" : 5
}
},
"backendIX" : "bk",
"backendMD" : "flat",
"backendSZ" : "json",
"index" : 1,
"maxIndexArrayLength" : 1024,
"maxIndexDepth" : 32,
"maxKeyLength" : 512,
"me" : "local",
"port" : 9138,
"root" : "/var/lib/indexdb",
"sync" : 1,
"syncTimeOut" : 30,
},
"db" : {
"metafs_alpha" : {
"items" : {
"count" : 1618,
"diskUsed" : 322494464,
"ix" : {
...
}
}
}
},
"diskFree" : 72957542400,
"diskTotal" : 234813100032,
"diskUsed" : 506613760,
"pid" : 27528
}
4.13. Meta
$i = $ixdb->meta($db,$c,$m)
$db= database$c= collection$m= meta (optional)types: object with key/value defining the typesindexing: object with key/value prioritize indexing
$ireports meta structuretypes&indexing
4.13.1. Types
By default all key/value are autotyped, first create or insert into a collection determines the type of the value.
In case you want to be sure a value is properly typed and indexed thereby (alphanumerical vs numerical),
therefore optionally define types:
string: value indexed alphanumericalnumber: value indexed numericaldate,time,percent
Example:
$ixdb->meta("myset","items",{
types => {
size => "number",
uid => "string",
},
indexing => { .. }
);
4.13.2. Indexing
By default all key/value are indexed, in case you want to omit or specially index a key,
define indexing, the priority or level of the key and optional the index-type:
- by default all keys are indexed
- define priority as
0, so the index is skipped, any other positive integer indicates priority - define optionally the index-type(s)
:' + index-type1 + [ ',' + index-type2 ... ] ]
Examples:
0
1
1:i
1:i,e
1:loc
Index Types
Note: This part is highly experimental, and might change soon.
i: case-insensitive, disregard case-sensitivity in the index; be aware: keys() will return keys all lowercasee: tune for regular expression queries (regex) using an additional trigram index; yet size of index is linear to length of value O(size(v)), e.g. indexing filenames with 5-20 chars, will create a 20x larger index, also increase amount of update writes 20xloc: (coming soon), geohash the key which should havelatandlongas sub-fields, e.g.location: { lat: .., long: .. }
i and e are combinable, e implies i functionality though.
Example:
$ixdb->meta("myset","items",{
types => { .. },
indexing => {
name => "1:i,e", # -- case insensitive & regular expression optimized
tags => "1:i", # -- case insensitive
keywords => "1:i", # " "
image => {
histocube => 0, # -- omit indexing this one
histogram => {
h => 0, # " "
s => 0, # etc.
l => 0,
a => 0
}
}
}
});
5. Tuning
5.1. ulimit/limit
All indexes are kept open so you need to increase limit of open files from the usual 1024 to 10000 at least or even higher.Increase the per process file descriptor/open-files limit:
% sudo su
ulimit -n 100000
/etc/security/limits.conf:
* soft nofile 10000
* hard nofile 10000
which takes effect one relogin, then
bash:
% ulimit -n 10000
% indexdb server &
% limit descriptors 10000
% indexdb server &
or you change the limits of the running indexdb process:
% ps aux | grep indexdb
kiwi 28199 1.9 0.1 91340 27324 pts/95 S+ Aug24 24:39 /usr/bin/perl ./indexdb server
% sudo prlimit --pid=28199 --nofile=10000:10000
6. Updates
Significant updates of this document:- 2017/07/24: 0.3.0: ixStore=
roRocksDB andlvLevelDB added - 2015/10/27: 0.1.26: update methods clarified
- 2015/09/27: 0.1.24: added
keys() - 2015/08/17: 0.1.18:
bxandlmbackend added - 2015/07/10: 0.1.14: sort, skip and limit in
find() - 2015/07/02: First version covering 0.1.12 (rkm)
- rkm: René K. Müller
 MetaFS.org - the metadata file system - Creative Commons CC 3.0 BY SA 2013-2019
MetaFS.org - the metadata file system - Creative Commons CC 3.0 BY SA 2013-2019