Table of Content
- 1. Notions
- 2. Fundamentals
- 3. Installed Programs
- 4. Mounting
- 5. Volumes
- 6. Time
- 6.1. Creation Time (ctime)
- 6.2. Modification Time (mtime)
- 6.3. Update Time (utime)
- 6.4. Origin Time (otime)
- 6.5. Access Time (atime)
- 7. Item Types
- 8. Technical Overview
- 9. Handlers
- 9.1. System Handlers
- 9.1.1. hash
- 9.1.2. version
- 9.1.3. image
- 9.1.4. video
- 9.1.5. audio
- 9.1.6. text
- 9.1.7. html
- 9.1.8. pdf
- 9.1.9. odf
- 9.1.10. epub
- 9.1.11. msword
- 9.1.12. location
- 9.1.13. unarchive
- 9.1.14. barcode
- 9.1.15. Various Other Handlers
- 9.2. Writing Handlers
- 10. Configuration
- 11. Backends
- 11.1. UNIX Filesystem
- 11.2. IndexDB
- 11.3. MongoDB / TokuMX
- 11.3.1. Shared & Dedicated MongoDB / TokuMX
- 11.3.2. Tuning MongoDB on Linux
- 11.3.3. MongoDB vs TokuMX
- 11.4. TokuMX Installation
- 11.5. PostgreSQL
- 11.6. Elasticsearch
- 12. Updates
- 13. Word Index
This handbook covers in-depth, and is recommended for users as well developers.
Note: this handbook covers always the current and most up-to-date version of , see Updates near the end of the document.
1. Notions
- metadata: data describing data
- volume: a volume is a closure which contains a dataset
- mount: a volume is mounted to an empty folder and appears there
- handler: a handler is a small program or function extracting more metadata
- trigger: a trigger is an event which occured to an item or the volume itself
2. Fundamentals
A volume is a collection of items, where each item has free defineable metadata in form of key/value pairs, whereas the value can be a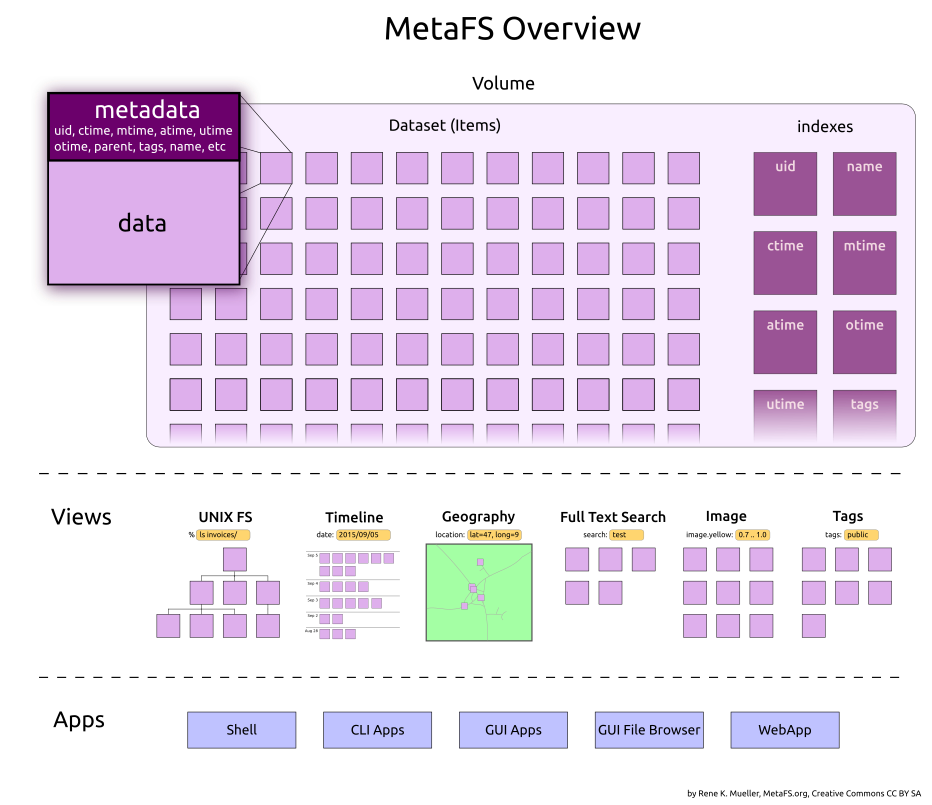
- string, e.g.
"hello world!" - integer, e.g.
108867 - float, e.g.
2037759.05721 - array (ordered list of values) or an
- object (unordered list of key/value pairs)
A few metadata keys are predefined for an item, and handled by the core of the file system:
uid: unique identifier, main reference & identifier of the itemotime: origin time, when data (virtual, digital or analog) came to be (media independent)ctime: creation time, when it was created in the file systemmtime: modification time, when it was modified (it can be earlier than ctime,cp -ppreserving modification time)atime: access time, when data was accessed for writing or readingutime: update time, it's when the item was updated the last time, including when metadata was changedsize: size of content in byteshash: the hash of the actual content (SHA256 hex)mime: MIME type of the actual content
name: name or filename; there are no restrictions in regards of character set, it can contain special character like [/, :, '"][1]parent: the item resides below a parent, must reference existinguid, (parent= 0 means its parent is root)type: type of item, by default not defined, if it's a folder its type isfoldertags: tags (array of terms)mode: UNIX user, group and others read/write/executable bits[2]
location.*, another handles image.* to store image specific data, or thumb.* contains thumbnail specific information, usable for a web frontend of .
- this might cause problems when accessing using the UNIX filesystem layer, but you can still access such an item using dedicated tools like
mls,mmeta,ormfind; the UNIX filesystem restriction should not limit capability, as the UNIX filesystem is just one way among other ways to access the dataset - Permissions aren't enforced yet but stored
3. Installed Programs
3.1. metafs
The main program is themetafs executable, it handles
- creating volumes,
- mounting and unmounting volumes and
- provides some basic information about volumes
alpha -> alpha
Alpha -> alpha
Beta01 -> beta01
%.Beta^$#@01 -> beta01
3.1.1. Usage
MetaFS usage: metafs [options] [<volume>] [<mountpoint>]
volume volume name, e.g. "alpha"
mountpoint empty directory, e.g. Alpha/
options:
--version print version only
-v, -vv or --verbose increase verbosity
-h or --help help message (this one)
-u or --umount unmount a volume
-f or --force force umount
-a or --all show all volumes (also unmounted)
-fg or --foreground remain in foreground (no daemonizing)
-c <conf> consider additional configuration
--conf=<conf> " "
-[variable] <value> override configuration, e.g. -root /opt/metafs/
--[variable]=<value> " "
3.1.2. Examples
Create new volume or use existing volume and mount it to the mountpoint:
% mkdir Alpha/
% metafs alpha Alpha/
% metafs -u alpha
% metafs -u Alpha/
% metafs alpha
<alpha> [/var/lib/metafs/volumes/alpha] on /home/kiwi/Alpha
% metafs
<alpha> [/var/lib/metafs/volumes/alpha] on /home/kiwi/Alpha
<beta> [/var/lib/metafs/volumes/beta] on /home/kiwi/Beta
% metafs -l
<alpha>
ctime: 2014/10/24 08:32:19.229 (17days 3hrs 39mins 36secs ago)
cwd: /home/kiwi
mount: /home/kiwi/Alpha
path: /var/lib/metafs/volumes/alpha
pid: 6849
stime: 2014/11/09 14:41:07.684 (21hrs 30mins 47secs ago)
uid: 14d0cbbc44a1ff3d3b69e7207f81ecf8-544a0e93-e3ab41
user: kiwi
version: MetaFS 0.3.19 (Perl v5.18.2, Fuse 0.16.1 / 2.9, MongoDB v0.705.0.0 / 2.4.9, Elasticsearch 1.14)
% metafs -l -a
...
3.2. metabusy
metabusy is a program which provides functionality of mls, mfind, mfsck, mfsinfo etc.
% metabusy ls
% mls
mls: listing items in a folder, likelsmfind: find anything in your filesystemmmeta: manipulate the metadata directmtag: tag a filemrm, andmurm: delete, undelete & purgemcp, copy item / file with metadatamdup, find duplicatesmfsck: perform filesystem checkmfsinfo: show filesystem infomtrigger: list, issue or purge triggersmarc: archive items / files
metabusy as well all shortcuts only work as long you are within a mounted volume, even if it's empty.
3.2.1. mls
% mls
% mls -l
% mls -l *.txt
% mls -l AA.txt
AA.txt
uid: fc55b6984f55bbf3586f5cd1c1155368db5647345303d3aed9390eaf052fee74
size: 15 bytes
mime: text/plain
otime: 2013/12/18 11:58:50.691 (1hr 1min 57secs ago)
ctime: 2013/12/18 11:58:50.691 (1hr 1min 57secs ago)
mtime: 2013/12/18 11:58:50.751 (1hr 1min 57secs ago)
utime: 2013/12/18 11:58:50.751 (1hr 1min 57secs ago)
atime: 2013/12/18 11:58:50.751 (1hr 1min 57secs ago)
hash: 1341566a646b4e759d3cf63e8e59be9c52d47d55701d7f941334b58030460eb6
text:
excerpt: this is a text
version: 1
% mls -L AA.txt
AA.txt
uid: fc55b6984f55bbf3586f5cd1c1155368db5647345303d3aed9390eaf052fee74
size: 15 bytes
mime: text/plain
otime: 1387364330.6916
ctime: 1387364330.6916
mtime: 1387364330.75151
utime: 1387364330.75151
atime: 1387364330.75151
hash: 1341566a646b4e759d3cf63e8e59be9c52d47d55701d7f941334b58030460eb6
text:
excerpt: this is a text
version: 1
% mls -j AA.txt
{
"atime": 1387364330.75151,
"ctime": 1387364330.6916,
"hash": "1341566a646b4e759d3cf63e8e59be9c52d47d55701d7f941334b58030460eb6",
"mime": "text/plain",
"mtime": 1387364330.75151,
"name": "AA.txt",
"parent": 0,
"otime": 1387364330.6916,
"size": 15,
"text": {
"excerpt": "this is a text"
},
"uid": "fc55b6984f55bbf3586f5cd1c1155368db5647345303d3aed9390eaf052fee74",
"utime": 1387364330.75151,
"version": 1
}
Options:
-llong listing, display all metadata of the item-tlist order according utime (not name alphabetically)-sort=keysort according specific key, e.g.-sort=sizeor-sort=text.uniqueWords[1]-rreverse list order-ushow uid not (file)name-Llong listing, but times and numbers aren't "pretty" formated but displayed raw (times in UNIX epoch, seconds since 1970/01/01 00:00:00 UTC, negative numbers represent earlier dates)-jlong listing as JSON-gdoes reverse lookup of location (lat/long -> location.city, location.country)[2]-o=formatlist entries with defined format, e.g. '-o=${name} (${uid}) ${mtime}'-ashow also internal metadata (only for debugging purposes)-econsider arguments are regular expression
To immitate the ls the options can be used combined, e.g. mls -ltr list items in reverse utime order, newest at the bottom.
3.2.2. mfind
mfind searches the volume; by default the name, tags, full text search (fts) and location (see conf/metabusy.conf the find section), or by a dedicated key:
% mfind something
% mfind -l something
% mfind -l -t something
% mfind -u something
% mfind -l -t -r '-o=${name}' something
% mfind -ltr '-o=${name}' something
% mfind hash:6c69466e5589c0d38a333....
% mfind uid:f6af7cb8431c505d9373bf42f3c4e...
% mfind type:folder
% mfind mime:image/jpeg
% mfind 'mime:image/*'
% mfind image.width:512
% mfind location:lat=40,long=7
% mfind location:Zurich
% mfind location:city=Zurich
% mfind location:dist=20km,city=Zurich
% mfind location:
% mfind -g '-o=${location.city},${location.country}: ${name}' location:
% mfind image.width:300..500
% mfind image.width:~300
or alternatively but slower:
% mfind 'image.width>300' 'image.width<500'
And more advanced querying using MongoDB's query data structure:
% mfind -qJ '\{"image.width":\{"$gt":300, "$lt":500\}\}'
Hint: The quotes '' are required when using < or > in mfind as otherwise the shell interprets it as stdin/stdout redirection.
3.2.2.1. Regular Expression
Regular expressions can be enabled with-e or enclose the term with two /:
% mfind -e -i -sort=size -r name:qemu`
% mfind -ei -sort=text.uniqueWords -r name:qemu`
% mfind -sort=size -r name:/qemu/i
qemu regular expression with case insensitivity enabled, sorted by size and in reverse order (largest first).
3.2.2.2. Equality, Inequality or Not Equal
Equality, inequalities and not equal:
:or=for equality, e.g.mime:image/jpegormime=image/jpeg!=is not equal, e.g.mime!=image/jpeg>,>=,<,<=are the inequalities 'greater than', 'greater than or equal', 'less than' or 'less than or equal', e.g.mtime<2015/01/01==is equality, and disregards any interpration such as Smart Value (described below) and regular expression, e.g.name==/text/searches for an item with name/text/.
% mfind 'mtime>2015/01/01'
% mfind 'image.width>=512'
3.2.2.3. Smart Expressions / Ranges
To query for a range (numeric, date, etc), without< or > to use two intuitive features are available:
~means about, e.g.mfind size=~10000[1]- num1
..num2 is range, e.g.mfind size=1000..2000, which equals to 1000 >=size<= 2000
% mfind size=15000..250000
% mfind 'image.width=512..640'
% mfind otime=~2014
% mfind otime=2013..2014
"date" like *time keys (mtime, otime, ctime etc), some meaningful ranges are applied:
otime=~2014looks for 2014/07/02 +/- 12 monthsotime=~2014/04looks for 2014/04/15 +/- 30 daysotime=~2014/04/20looks for 2014/04/20 12:00:00 +/- 24 hours etcotime=~2013..2014looks for 2013/01/01 00:00:00 >= to < 2015/01/01 00:00:00 (<= 2014/12/31 23:59:59 would miss 1 second since seconds are stored millisecond exact)
3.2.2.4. Smart Values
Smart values or interpretation of values is included inmfind when querying:
% mfind 'mtime<1hr ago'
% mfind 'size>10MB'
% mfind 'image.pixels=~10M'
Smart values types explained and described in the required details below.
3.2.2.4.1. Absolute Dates
Absolute dates in querying is done with some comfort for keys which aredate defined[1]:
Y*AD(Anno Domini), e.g.120AD(year 120)Y*BC(Before Christ), e.g.20BC(year -19)YYYY, e.g.2015YYYY/MorYYYY/MM, e.g.2015/3or2015/03YYYY/MM/DorYYYY/MM/DD, e.g.2015/3/15,2015/3/5,2015/09/5, or2015/09/01YYYY/MM/DD HH:MM, e.g.2015/01/15 1:03or2015/1/3 14:00YYYY/MM/DD HH:MM:SS, e.g.2015/1/15 1:03:05or2014/12/1 21:15:03
% mfind 'mtime>2015'
% mfind 'mtime<2014/12'
% mfind 'mtime<2014/12/1'
% mfind 'otime<20BC'
Depending on context, the date is completed, e.g. when setting with mmeta the half of year, half or month or day is assumed, if it's not defined: 1980 means 1980/07/02 12:00:00;
yet with mfind and Smart Expression like range with .., e.g. 1980..1990 is interpreted 1980/01/01 00:00:00 >= date < 1991/01/01 00:00:00.
3.2.2.4.2. Relative Timing
Relative timing in querying is possible using the notion:{number} {unit} agoorahead: whereasunitis an abbreviation of- seconds (
s,sec,secs,second,seconds) (default) - minutes (
m,mi,min,mins,minute,minutes) (60 secs) - hours (
h,hr,hrs,hour,hours) (60 minutes) - days (
d,dy,day,days) (24 hours) - weeks (
w,wk,wks,week,weeks) (7 days) - months (
mo,mos,mon,mons,month,months) (30.5 days) - years (
y,yr,yrs,year,years) (365.25 days) - decades (
de,dec,decades) (10 years) - centuries (
ce,cen,cents,century,centuries) (100 years) - millenia (
mil,millenia) (1000 years)
- seconds (
1m ago, 1min ago, 3mins ago, 20 mins ago, 1.5d ago, 10days ahead, 1.5 mo ago, 10yr ago etc.
most useful in regards of *time metadata like utime, mtime, ctime etc, but also in semantics: timings.
% mfind 'utime<1min ago'
% mfind 'mtime<10d ago'
% mfind 'semantics.timings.time>20yr ago'
3.2.2.4.3. Memory & Storage Size
Common way to abbreviate memory sizes and storage sizes in bytes:{number}{unit}: whereasunitisKBorKiB, Kilobytes (1024 bytes),MBorMiB, Megabytes (10242 bytes)GBorGiB, Gigabytes (10243 bytes)TBorTiB, Terabytes (10244 bytes)PBorPiB, Petabytes (10245 bytes)EBorEiB, Exabytes (10246 bytes)ZBorZiB, Zettabytes (10247 bytes)YBorYiB, Yottabytes (10248 bytes)
1.5KB, 10MB, 100GB, 2.3TB
% mfind 'size>10MB'
% mfind 'size>100GB'
Regardless whether hard-disks manufactures try to redefine MB, GB, TB as 1000n, it's 1024n.
3.2.2.4.4. Large Numbers
Common way to abbreviate large numbers:{number}{unit}: where asunitisKfor thousand(s) (10001)Mfor million(s) (10002)Gfor giga(s) (10003)Ttera(s) (10004)Ppeta(s) (10005)Eexa(s) (10006)Zzetta(s) (10007)Yyotta(s) (10008)
5M for 5,000,000
% mfind 'image.pixels>=5M'
3.2.2.4.5. Distances
Common way to abbreviate distances:{number} {unit}: whereasunitis an abbreviation of- nanometer (
nm) (10^-9 m) - micrometer (
um) (10^-6 m) - millimeter (
mm) (10^-3 m) - centimeter (
cm) (10^-2 m) - decimeter (
dm) (10^-1 m) - meter (
m,mt) - kilometer (
km) (10^3 m) - inches (
",in) (0.0254 m) - feet (
',ft) (0.3048 m) - miles (
mi) (1609.34 m) - nautic miles (
nmi) (1852 m) - astronomical unit (
au,AU) (149,597,870.7 m) - lightyears (
ly) (9.4607 10^15 m) - parsecs (
pc) (3.0856776 10^16 m)
- nanometer (
15cm, 28km, 12mi, 2", 12ft
% mfind location:city=Zurich,dist=300km
% mfind location:city=Denver,dist=250mi
3.2.2.5. Time Duration
Common times (duration):{number} {unit}: whereasunitis an abbreviation of- nanoseconds (
ns) (10^-9 s) - microseconds (
us) (10^-6 s) - milliseconds (
ms) (10^-3 s) - seconds (
s,sec,secs,second,seconds) (default) - minutes (
m,mi,min,mins,minute,minutes) (60 secs) - hours (
h,hr,hrs,hour,hours) (60 minutes) - days (
d,dy,day,days) (24 hours) - weeks (
w,wk,wks,week,weeks) (7 days) - months (
mo,mos,mon,mons,month,months) (30.5 days) - years (
y,yr,yrs,year,years) (365.25 days) - decades (
de,dec,decades) (10 years) - centuries (
ce,cen,cents,century,centuries) (100 years) - millenia (
mil,millenia) (1000 years)
- nanoseconds (
150ms, 2mins, 18hrs, 62days, 12wks, 2cen, 6mil
% mfind audio.duration=4min..8min
% mfind video.duration=50min..2hrs
3.2.2.5.1. Percent
- {number}
%, e.g.20.5%
31.5% for 0.315
% mfind 'image.theme.black>=30%'
Options:
-vor-vvetc, increases verbosity-llong listing, display all metadata of the item-tlist order according utime (not name alphabetically which is default)-sort=keysort according specific key, e.g.-sort=sizeor-sort=text.uniqueWords[1]-etreat term as regular expression, same as/term/, also when the term contains * or ?-eenabled[2]-icase insensitivity in case of-e, equivalent to/term/i[3]-rreverse list order-ushow uid not (file)name-Llong listing, but times and numbers aren't "pretty" formated but displayed raw (times in UNIX epoch, seconds since 1970/01/01 00:00:00 UTC, negative numbers represent earlier dates)-jlong listing as JSON-gdoes reverse lookup of location (lat/long -> location.city, location.country will be set)[4]-o=formatlist entries with defined format, metadata values are displayed using${key}, e.g.'-o=${name} (${uid}) ${mtime}'-ashow also internal metadata (only for debugging purposes)-quse query expression (JSON default), see advanced querying-Juse JSON as query expression language-Puse Perl as query expression language-fa file as input ('-' will be STDIN)
The combination of all the mentioned features, mfind is a powerful tool:
Examples
% mfind 'mtime:~10days ago'
% mfind 'image.pixels=5..10M'
% mfind 'size=10..50MB'
% mfind 'ctime=2015/01..2015/06'
% mfind 'mtime=~2014'
- it is important that handlers define the type of the metadata in conf/handler.conf
"types": { }properly, so the sorting is correctly done as well, e.g. alphabetically for"string"or numerically as of"number"or"time"done - currently regular expression search is rather slow, at a later time faster algorithms are used, see Regular Expression Matching with a Trigram Index by Cox (2012)
- full text search (fts) is default case insensitive
- it will not write back the lookup but only use it for display
3.2.3. mtag
mtag allows to add, set, or remove tags:
% mtag +meadow violet_sunset.jpg
tags: meadow
% mtag +red,orange violet_sunset.jpg
tags: meadow,red,orange
% mtag -red violet_sunset.jpg
tags: meadow,orange
% mtag violet_sunset.jpg
tags: meadow,orange
% mtag =blue violet_sunset.jpg
tags: blue
% mtag violet_sunset.jpg
tags: blue
% mtag = violet_sunset.jpg
tags:
% mtag --key=mytags +red sample.txt
mytags: red
Options:
--key=key, alternative key (default 'tags'), e.g.--key=mytags
3.2.4. mmeta
mmeta allows to add and remove metadata:
% mmeta "--extra=extra field with some information" AA.txt
extra: extra field with some information
% mmeta --extra AA.txt
extra: extra field with some information
% mmeta --extra= AA.txt
extra removed
% mmeta -l "--extra=something else" AA.txt
extra: something else
AA.txt
uid: c8b93ea21191343b49b8816d18a7f34f47c47aeb38e3512bf64cd9784f566f6b
size: 15 bytes
mime: text/plain
otime: 2013/12/15 14:14:27.333 (23hrs 5mins 4secs ago)
mtime: 2013/12/15 14:14:27.350 (23hrs 5mins 4secs ago)
ctime: 2013/12/15 14:14:27.333 (23hrs 5mins 4secs ago)
utime: 2013/12/15 14:14:27.350 (23hrs 5mins 4secs ago)
atime: 2013/12/15 14:14:27.350 (23hrs 5mins 4secs ago)
hash: 1341566a646b4e759d3cf63e8e59be9c52d47d55701d7f941334b58030460eb6
extra: something else
text:
excerpt: this is a text
version: 1
You can also set a location, either via location.city and preferable by location.country (universal country code) to avoid ambiguity, or via location.lat / location.long - whatever is missing and can be determined will be added (by default for now), e.g. set city/country, and lat/long will be determined:
% mmeta -l --location.city=Steinhausen --location.country=CH AA.txt
location.city: Steinhausen
location.country: CH
location.lat: 47.1951
location.long: 8.48581
location.elevation: 425
AA.txt
uid: c8b93ea21191343b49b8816d18a7f34f47c47aeb38e3512bf64cd9784f566f6b
size: 15 bytes
mime: text/plain
otime: 2013/12/15 14:14:27.333 (23hrs 5mins 58secs ago)
ctime: 2013/12/15 14:14:27.333 (23hrs 5mins 58secs ago)
mtime: 2013/12/15 14:14:27.350 (23hrs 5mins 58secs ago)
utime: 2013/12/15 14:14:27.350 (23hrs 5mins 58secs ago)
atime: 2013/12/15 14:14:27.350 (23hrs 5mins 58secs ago)
hash: 1341566a646b4e759d3cf63e8e59be9c52d47d55701d7f941334b58030460eb6
extra: something else
location:
city: Steinhausen
country: CH
elevation: 425
lat: 47.1951
long: 8.48581
text:
excerpt: this is a text
version: 1
% mmeta --location= AA.txt
location removed
% mmeta --location.lat=40 --location.long=7 AA.txt
location.lat: 40
location.long: 7
location.city: Alghero
location.country: IT
% mmeta --location.lat=51.380008 --location.long=-0.281236 Tolworth_tower_gigapixel_panorama.jpg
location.lat: 51.380008 deg
location.long: -0.281236 deg
% mmeta "--location.lat=51 22' 48.03\" N" "--location.long=0 16' 52.45\" W" Tolworth_tower_gigapixel_panorama.jpg
location.lat: 51.380008 deg
location.long: -0.281236 deg
Setting dates, e.g. mtime and otime are permitted to be changed (ctime, utime, atime have to be consistant and remain system controlled)
or image.mtime or text.mtime can be altered or set: [1]
% mmeta '--mtime=1848/01/01 01:02:03' AA.txt
mtime: 1848/01/01 01:02:03.000 (167yrs 1month 9days 16hrs 37mins 21secs ago)
% mmeta -L '--mtime=1848/01/01 01:02:03' AA.txt
mtime: -3849980277
% mmeta --otime=1848 AA.txt
otime: 1848/06/15 00:00:00.000 (166yrs 7months 27days 17hrs 39mins 44secs ago)
% mmeta --otime=1848/04 AA.txt
otime: 1848/04/15 00:00:00.000 (166yrs 9months 27days 17hrs 39mins 52secs ago)
% mmeta --otime=1848/04/01 AA.txt
otime: 1848/04/01 12:00:00.000 (166yrs 10months 10days 5hrs 40mins 0sec ago)
% mmeta '--otime=2 weeks ago' AA.txt
otime: 2015/01/27 17:40:07.980 (14days 0hr 0min 0sec ago)
mfind otime:1848..1849 it searches 1848/01/01 00:00:00 to 1849/12/31 23:59:59.999999.
It also means if you know the data exact, set it exact, month, day, hour, minute or second exact if possible, otherwise the undefined parts will be assumed somewhere in between.
In case you want to switch off the Smart Value parsing, and ensure the data is copied verbatim use == instead of = or ::
% mmeta --otime==10000 AA.txt
otime: 1970/01/01 02:46:40.000 (45yrs 1month 9days 14hrs 59mins 35secs ago)
% mmeta -L --otime==10000 AA.txt
otime: 10000
Options:
-llong listing, display all metadata of the item-uuse uid instead of (file)name-Llong listing, but times and numbers aren't "pretty" formated but displayed raw (times in UNIX epoch, seconds since 1970/01/01 00:00:00 UTC, negative numbers represent earlier dates)-jlong listing as JSON-ashow also internal metadata (only for debugging purposes)
3.2.5. mrm
By default it's fine to userm to delete files, and if trash bin is enabled in conf/metafs.conf, the item will reside in the trash, so you can
- undelete or
- purge entirely
mrm, e.g. view the trash bin:
% mrm -t
DIR/
XX
total 2 items (24 bytes)
and undelete item(s):
% mrm --undelete DIR XX
DIR bbcc6883ccc6c1a84883520853b7957d74a4e1b7c4949b9ae31f80e0cc7af858 restored
XX c95423acdde05abfe79bc1e279e471af2c683ec5ab24d99028c4110593ca8cb0 restored
% murm DIR XX
DIR bbcc6883ccc6c1a84883520853b7957d74a4e1b7c4949b9ae31f80e0cc7af858 restored
XX c95423acdde05abfe79bc1e279e471af2c683ec5ab24d99028c4110593ca8cb0 restored
and finally to purge the items in the trash bin:
% mrm -p
purging trash, done.
total of 2 items (24 bytes) freed
Options:
-t: view trash bin-u: use uid instead of (file)names--undelete: undelete items from the trash (same asmurm)-r: delete recursively, e.g.mrm -r DIR/-p: purge trash bin
3.2.7. mdup
mdup lists possible duplicates in content (for now disregards the metadata):
% cp open-source-logo.png sample.png
% cp BB DIR/XY
% mdup
open-source-logo.png
== sample.png
BB
== DIR/XY
% mdup sample.png
open-source-logo.png
== sample.png
hash-handler needs to be enabled (by default it is) in metafs.conf so duplicates can be found.
3.2.8. mfsck
mfsck provides filesystem check (fsck):
% mfsck
volume: alpha
uid: 415ecba1d21aae6e2c1f384b312e236f946c15aa23d630d2e84c587738990c70
ctime: 2014/08/21 05:53:52.040 (28days 9hrs 18mins 42secs ago)
path: /var/lib/metafs/volumes/alpha
mount: /home/kiwi/mount
pass 1: data
19 of 19 (100.0%), eta 00s, elapsed 00s, 7191.4 p/s
pass 2: metadata
18 of 18 (100.0%), eta 00s, elapsed 00s, 0.0 p/s
pass 3: hash
19 of 19 (100.0%), eta 00s, elapsed 00s, 265.7 p/s
pass 4: version
1 of 1 (100.0%), eta 01s, elapsed 00s, 0.0 p/s
pass 5: fts
pass 6: snapshot
total: 19 items (18 plain, 1 folder)
- data: check data files (existance)
- metadata: data files reverse to metadata consistency
- hash: check data integrity
- and the others do check their own integrity (e.g. version, fts, snapshot etc)
Options:
--perform=pass1,passN, e.g.--perform=hash,metadata--skip=pass1,passN, e.g.--skip=fts,hash
By default all checking is done, with --skip= individual passes can be skipped, or --perform= or direct list the passes to perform:
% mfsck
% mfsck metadata hash
% mfsck --perform=metadata,hash
% mfsck --skip=hash,fts
3.2.9. mfsinfo
mfsinfo displays some basic information of the filesystem:
% mfsinfo
volume: alpha
uid: 415ecba1d21aae6e2c1f384b312e236f946c15aa23d630d2e84c587738990c70
ctime: 2014/08/21 05:53:52.040 (28days 9hrs 20mins 55secs ago)
path: /var/lib/metafs/volumes/alpha
mount: /home/kiwi/mount
fts size: 454,656
location geonames: 138,673
queue database: 0
queue triggers: 0
snapshot count: 0
version dists: 1:17, 17:1
total size: 10,597,508 bytes
total items: 19
indexes(default)triggers(default): trigger queue, and eta until emptystatistics: provide detailed statisticsmongodb(default): internal mongodb informationtrash(default)size(default): calculate sum of all items (time consuming)- name of any handler, e.g.
hash,snapshotor so; not all handlers supportfsinfotrigger
-lmore details (e.g. statistics)-qdisplay trigger queue-wdisplay all indexed words-aall switches listed above-joutput JSON-Lmore details but no formating
-l -q is equal to -lq.
% mfsinfo -l
% mfsinfo -a
% mfsinfo triggers
% mfsinfo trash
3.2.10. mtrigger
mtrigger provides way to deal with the triggers, to fire a trigger to a handler:
mtrigger [handler] [trigger] [uid] ...
mtrigger [handler] [trigger] [file] ...
where uid or file are optional.
Examples:
% mtrigger text update * -- all items in current dir
% mtrigger text update *.txt -- all .txt items in current dir
% mtrigger text update '*' -- all items matching MIME for text-handler
handler: you find the available handlers inhandlers/(e.g./var/lib/metafs/handlers)trigger:init,update, etc.
"*" means all items in the volume.
Note: handlers only accept often only certain mime-types flavoured items, which are defined in metafs.conf.
So given the handler accepts those mime-types properly, it's safe to use "*" to be sure all processed metadata are up-to-date again.
The mtrigger command is only used:
- if something went really bad, and recover metadata which is processed via handlers
- a volume is transfered while trigger queue was still non-empty
- special handlers have their own triggers, e.g.
snapshot-handler hasmksnaptrigger
% mtrigger queue -- list trigger queue
% mtrigger purge -- purge trigger queue
3.2.11. marc
marc provides simple archiving functionality, using a new archive file format with the same name marc:
marc [options] command archive [ items ... ]
whereas command are single letters (following the tar command notion):
ccreate archive or overwrite existingaadd items to existing archive or create new archivetshow table of contentxextract archive
vverbose, display what it does at creation, extraction or addingzcompress (only needed for creation)ppretend, don't do any changes but show what would be done
- stdin or stdout depending on functionality is considered.
and options are following:
--exclude=regexexclude certain entries as defined via regular expression, e.g.marc '--exclude=.txt$' cv ../all.marc .
.marc to indicate the file format as you likely use the archive outside of volume, within it will be recognized as MIME type application/x-marc.
% marc c alpha.marc *.txt DIR/
% marc t alpha.marc
toc: marc (v1,uncompressed)
toc: 76b68ccf68b87c6084f0d2584c1166a7-5468cbdf-d28403 AA.txt (783+15)
toc: c67afcde66d99cbabbfe3b8119a620e3-54bd20d2-8e23f2 bible.txt (1713+5504597)
toc: 31caf4a25ff00fa66fb830880f401e45-54bd164a-8e23f1 mahabharata.txt (1714+1382551)
toc: 304e0581e94356dc158c82cd2876e207-54ce76e1-27664a quantities.txt (6541+825)
toc: 3c0a61c0eb82b76d5fa1461b77d633a9-5468cbe2-d2840b shakespeare-midsummer-16.txt (13166+96439)
toc: d9275664d2edbc7ecb886d6745e2019d-5468cbe3-d28412 timings.txt (4038+174)
toc: 79452b0181914ac4c10339c85c05e56a-5468cbe2-d28408 DIR (452)
toc: c0438178471ee5d129b9fd02f83b04ff-5468cbe2-d28409 XX (826+24)
total 8 items, 29,233+6,984,625 bytes
% marc x alpha.marc
% marc av alpha.marc *.jpg
add: marc (v1,uncompressed)
add: 400b567447146bea210748356be0c77d-54ba9a90-ef6717 20130914_140844.jpg (115615+3517355)
add: 51dfa485449e2b7b834aafb0d8979be1-54d7a542-624240 20140730_112500.jpg (116079+2771122)
add: 631147443d31a021c2a0303e597bf82d-54d7a542-624241 20140730_191555.jpg (119188+3142812)
add: 6e5318e9127f2c00e2b4cee73e9011f6-54bbe2c5-ef6719 the-starry-night-1889.jpg (121357+2684897)
add: da37cac949dacd8b5893080969f1687a-54bba873-ef6718 venus.jpg (111489+366826)
add: 27a64d5ce00622e5a2d2dd488d10e3fc-54be2ecb-5615ea violet_sunset.jpg (119841+44788)
total 6 items added, 703,569+12,527,800 bytes
% marc cv - . | (ssh backup.server.com "cd Alpha/; marc xv -")
The marc file format itself is explained in the Cookbook: Archiving.
3.2.12. Additional Functionality
There are commands available without program shortcuts, which means they need to be invoked withmetabusy ahead, like metabusy backup.
3.2.12.1. format
Formating a volume is emptying a volume entirely:% metabusy format
3.2.12.2. backup
Backup a volume is needed when you want to- backup a volume
- transfer a volume to another machine (with the same backend infrastructure)[1]
% metabusy backup
3.2.12.3. restore
Restore a volume from a backup or another machine:% metabusy restore
3.2.13. metabusy.conf
Inconf/metabusy.conf you can define the defaults for metabusy functionality:
{ # -- metabusy and related programs (shortcuts) default settings:
"find": {
"searchDefault": [ "name", "tags", "fts", "location" ],
"argsDefault": {
"name": { "e": 1, "i": 1 },
"tags": { "e": 1, "i": 1 },
"fts": { },
"location": { "dist": 10000 }
},
"maxResults": 0, # -- unlimited (be aware of timeouts)
# "maxResults": 100000,
"autoProgress": 100000 # -- show progress bar if more than 100,000 entries
},
"ls": { },
"meta": { },
"tag": { },
"cp": { },
"rm": { },
"dup": { },
"trigger": { },
"format": { },
"restore": { },
"backup": { },
"fsck": { },
"fsinfo": { },
}
4. Mounting
4.1. metafs vs mount
is implemented using FUSE (Filesystem in Userspace), and a volume can be mounted usingmount as well.
For the following examples alpha is the volume name and Alpha/ the mountpoint.
% metafs alpha Alpha/
% sudo mount -t metafs alpha Alpha/
metafs can be executed as normal user, where as mount root is required.
4.2. /etc/fstab
So you can add a permanent entry to/etc/fstab:
<volume> <mountpoint> metafs user 0 0
for example:
alpha /home/me/Alpha/ metafs user 0 0
beta /home/me/Beta/ metafs user 0 0
Also, once you added your entries in /etc/fstab, you can use mount and umount as well, e.g. sudo mount Alpha/ or sudo umount Alpha/.
So, theoretically, at every boot you can have your volumes mounted right away, but it's unlikely that at time the disks are mounted the other services like MongoDB / TokuMX and Elasticsearch (if enabled) are running already[1], this means you have to add in /etc/rc.local following line:
(sleep 10 && mount -a) &
Hint: With "Ubuntu Desktop Edition" it will complain that some mounts failed and ask to hit 'S' for skip, so, this approach is more recommended for server usage.
5. Volumes
5.1. Create & Mount Volume
First create the mountpoint, an empty folder/directory:% mkdir Alpha/
metafs creates a new volume, unless it exists already, when you mount a volume:
% metafs alpha Alpha/
/var/lib/metafs/volumes/alpha.
or create or mount a volume by a path, given myvolumes/ folder/directory exists:
% metafs myvolumes/alpha Alpha/
5.2. Backup Volume
uses MongoDB or TokuMX and Elasticsearch services, in order to backup the entire volume:% cd Alpha/
% metabusy backup
/var/lib/metafs/volumes/alpha); then you can tar that directory and store or transfer it to another machine with the same backend infrastructure.
Note: this functionality will change soon.
See also marc (MetaFS Archive) command and format, to store datasets backend independent.
5.3. Restore Volume
In order to restore a volume of a previous backup (same backend infrastructure), ensure the data of the volume is current (e.g./var/lib/metafs/volumes/alpha), then mount the volume using metafs and then:
% cd Alpha/
% metabusy restore
Note: this functionality will change soon.
See also marc (MetaFS Archive) command and format, to store datasets backend independent.
5.4. Format Volume
In case you want to reset and empty a volume, to start from scratch:% cd Alpha/
% metabusy format
Internally a format event is sent to all handlers if they defined to receive it in conf/metafs.conf, and near the end of the formatting an init event as if the volume was re-mounted.
6. Time
All times are in float UNIX epoch, seconds since 1970/01/01 00:00:00 UTC, with microseconds (usec or µsec) precision, although just 3 digits are displayed inmls and other tools.
Since the times aren't stored as integer but float, it also means there is no 32 bit overflow happening in year 2038. Further, it enables to backdate data to earlier than 1970 by using a negative time.
6.2. Modification Time (mtime)
mtime is the time of the last modification of the data, which may be earlier than ctime.
- new item:
ctime==mtime - existing item copied into :
ctime<=mtime
6.3. Update Time (utime)
utime has been introduced to to reflect update of data or metadata, e.g. trigger meta in a handler is processed.
- new item:
utime==mtime==ctime - existing item:
utime==ctime
6.4. Origin Time (otime)
otime has been introduced to to reflect the time the data origins from, independent of the media.
For example,
- a painting is started in May 5, 1876 (
image.painting.ctime), and - finished in June 3, 1876 (
image.painting.mtime), and - photographed with a digital camera in October 5, 2005 (
image.ctime,image.mtime&mtime), and - copied to the local filesystem in February 8, 2015 (
ctime).
otime is derived from image.painting.mtime, either manually by you who set image.painting.ctime/mtime and then also manually or automatically[1] to otime,
best consult the Cookbook: Mapping Keys for best practice in this regards.
ctimeis about when the data came to the filesystem,mtimewhen the digital data was last modified,otimethe data or information came to be, even before translated or captured digitally.
7. Item Types
type in the item is used to indicate the type of the item, if it's not set, then it's a normal or default item.
7.1. Folder
type: folder indicates an UNIX ~folder, it's a node without data~.
Other items have the parent set to an item with type: folder, hence are files in that folder - this the first use case of : acting as UNIX filesystem.
mls shows items with type: folder with a trailing '/', alike ls does.
% mls
AA.txt
DIR/
7.2. Node
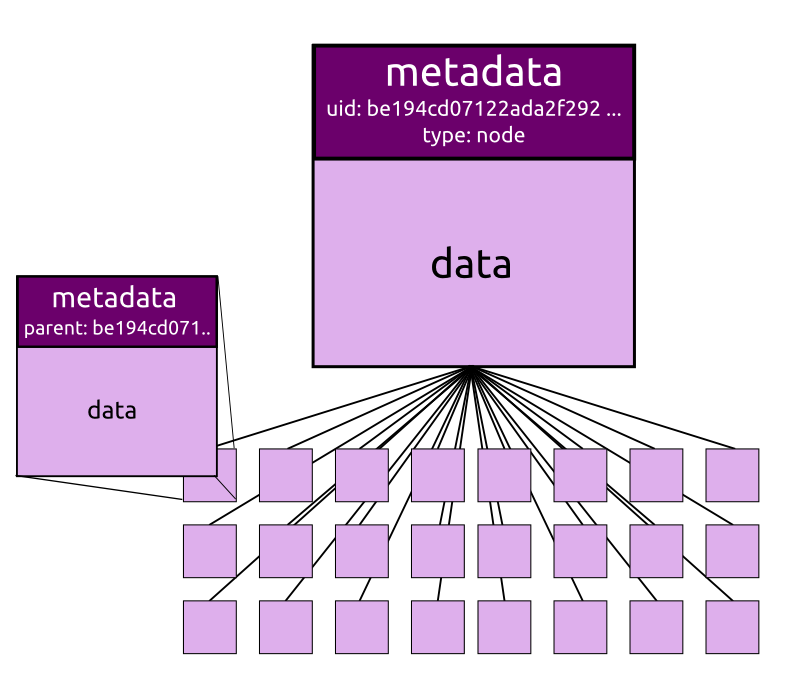
type: node indicates a node with data, where other items belong to. The sub-nodes are those items, which have parent set to the item with type: node.
There is no UNIX filesystem equivalent of a node as such, as a folder or directory cannot and does not hold data as well.
In order to make a node visible under a filesystem, each node has two visible entries, mls shows items with type: node twice:
- file aspect of the node
- folder aspect of the node
% mls
sample.mp4
sample.mp4+/
One of the use cases of node is when an item is exploded into its pieces, e.g. a video into still images.
The sub-nodes have then parent set to the item with type: node, and because parent is used as reference, mls lists the sub-nodes as files of the node seen as folder.
7.3. Custom Types
You may define your own types, aside of folder and node; yet as a reminder, the item type covers functionality and topography, but not content.
Rather try to adapt existing item type functionality than invent your own, as if a new type is introduced then metabusy toolset might require an update (mls, mfsck, mfsinfo etc).
8. Technical Overview
The current implementation of is done with Linux FUSE (Filesystem in Userspace) which gives an interface to low level operations of dealing with the filesystem, like creating new files, entering a folder etc; as such, all existing programs dealing with the UNIX filesystem still work, additionally specific programs which provide access to the extended -functionality: metadata.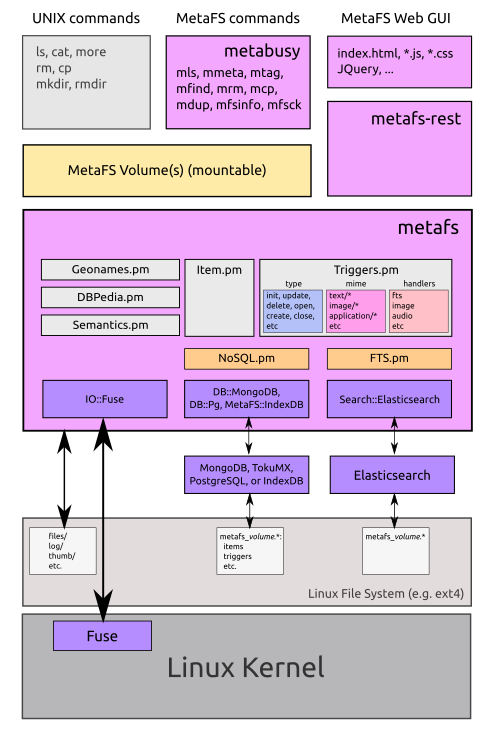
As backend MongoDB or TokuMX is used, as well Elasticsearch for the full text search capability.
9. Handlers
Handlers are there to extract metadata from the data, or provide additional functionality like versioning, syncing between machines etc.
9.1. System Handlers
Following handlers are included in current :
9.1.1. hash
Thehash-handler computes the SHA256 hash digest:
% mmeta --hash AA.txt
hash: 1341566a646b4e759d3cf63e8e59be9c52d47d55701d7f941334b58030460eb6
% sha256sum AA.txt
1341566a646b4e759d3cf63e8e59be9c52d47d55701d7f941334b58030460eb6 AA.txt
9.1.3. image
Theimage-handler processes all image/* and PDFs, creates an thumbnail and processes other images data, like extract EXIF data if available.
MIME: image/* and application/pdf
image/*: determines width and height of image,image.{width,height}.- create a thumbnail in
thumb/and setsthumb.{width,height,src,mtime}. image.vectorcontains R,G,B values summarizedimage.color.type:bw,gray,monochrome,limitedorfullimage.illumination:bright,balancedordarkimage.themecontains a set of colors and their normalized ratio, e.g.image.theme.whiteis 0.03, which means 3% of the image is white.
See Cookbook: Images with more details of image.* metadata and how to search for particular colors in images.
9.1.3.1. Image EXIF

image.EXIF.*which can be comprehensive (see example below).
image.mtime & mtime of the file is overriden, the ctime of the file remains up-to-date (mtime is older than ctime like with cp -p).
Unfortunately EXIF "CreateDate" does not contain any timezone information.
For example:
% mls -l 20130914_140844.jpg
20130914_140844.jpg
uid: 6af8de2116a3a8408f8cf7a579ed0f0a-545886a3-6edfc5
size: 3,517,355 bytes
mime: image/jpeg
otime: 2013/09/14 12:08:16.000 (1yr 1month 26days 18hrs 45mins 56secs ago)
ctime: 2014/11/04 07:56:19.479 (6days 22hrs 57mins 53secs ago)
mtime: 2013/09/14 12:08:16.000 (1yr 1month 26days 18hrs 45mins 56secs ago)
utime: 2014/11/04 07:56:19.656 (6days 22hrs 57mins 53secs ago)
atime: 2014/11/10 13:24:17.172 (17hrs 29mins 55secs ago)
mode: rwxr--r--
hash: f74b72a8cf30087cca26bdacd6d803f884d163930f70f14a6a89c177ae50b18e
image:
EXIF: {
Aperture: 2.7
ApertureValue: 2.6
BitsPerSample: 8
BrightnessValue: 9.76
ColorComponents: 3
ColorSpace: sRGB
Compression: "JPEG (old-style)"
CreateDate: "2013:09:14 14:08:43"
DateTimeOriginal: "2013:09:14 14:08:43"
Directory: /home/kiwi/Projects/MetaFS/volumes/alpha/files/6a/f8
EncodingProcess: "Baseline DCT, Huffman coding"
ExifByteOrder: "Little-endian (Intel, II)"
ExifImageHeight: 2448
ExifImageWidth: 3264
ExifToolVersion: 9.70
ExifVersion: 0220
ExposureCompensation: 0
ExposureMode: Auto
ExposureProgram: "Aperture-priority AE"
ExposureTime: 1/1585
FNumber: 2.7
FileAccessDate: "2014:11:04 08:56:19+01:00"
FileInodeChangeDate: "2014:11:04 08:56:19+01:00"
FileModifyDate: "2014:11:04 08:56:19+01:00"
FileName: de2116a3a8408f8cf7a579ed0f0a-545886a3-6edfc5
FilePermissions: rwxr--r--
FileSize: "3.4 MB"
FileType: JPEG
Flash: "Off, Did not fire"
FlashpixVersion: 0100
FocalLength: "4.0 mm"
FocalLength35efl: "4.0 mm"
GPSAltitude: "477.3 m Above Sea Level"
GPSAltitude1: "477.3 m"
GPSAltitudeRef: "Above Sea Level"
GPSDateStamp: 2013:09:14
GPSDateTime: "2013:09:14 12:08:16Z"
GPSLatitude: "47 deg 9' 9.41" N"
GPSLatitude1: "47 deg 9' 9.41""
GPSLatitudeRef: North
GPSLongitude: "8 deg 30' 33.05" E"
GPSLongitude1: "8 deg 30' 33.05""
GPSLongitudeRef: East
GPSPosition: "47 deg 9' 9.41" N, 8 deg 30' 33.05" E"
GPSProcessingMethod:
GPSTimeStamp: 12:08:16
GPSVersionID: 2.2.0.0
ISO: 40
ImageHeight: 2448
ImageHeight1: 240
ImageHeight2: 2448
ImageSize: 3264x2448
ImageUniqueID: SBEF02
ImageWidth: 3264
ImageWidth1: 320
ImageWidth2: 3264
LightValue: 14.8
MIMEType: image/jpeg
Make: SAMSUNG
MakerNoteVersion: 0100
MaxApertureValue: 2.6
MeteringMode: "Center-weighted average"
Model: GT-I9100
ModifyDate: "2013:09:14 14:08:43"
Orientation: "Horizontal (normal)"
Orientation1: "Horizontal (normal)"
ResolutionUnit: inches
ResolutionUnit1: inches
SceneCaptureType: Standard
ShutterSpeed: 1/1585
ShutterSpeedValue: 1/1585
Software: I9100XWLSS
ThumbnailLength: 45752
ThumbnailOffset: 1142
UserComment: "User comments"
WhiteBalance: Auto
XResolution: 72
XResolution1: 72
YCbCrPositioning: Centered
YCbCrSubSampling: "YCbCr4:2:2 (2 1)"
YResolution: 72
ThumbnailLength: 45752
ThumbnailOffset: 1142
UserComment: "User comments"
WhiteBalance: Auto
XResolution: 72
XResolution1: 72
YCbCrPositioning: Centered
YCbCrSubSampling: "YCbCr4:2:2 (2 1)"
YResolution: 72
YResolution1: 72
}
height: 2448
vector: {
1x1: [ [ 48.1481481481481, 49.4814814814815, 49.962962962963 ] ]
3x3: [ [ 208, 219, 236 ], [ 206, 220, 239 ], [ 124, 134, 143 ], [ 144, 152, 153 ], [ 139, 139, 130 ], [ 67, 70, 68 ], [ 122, 123, 114 ], [ 158, 149, 139 ], [ 132, 130, 127 ] ]
}
width: 3264
location:
body: Earth
elevation: 477.3
lat: 47.1526138888889
long: 8.50918055555556
parent: 0
thumb:
height: 375
mtime: 1415087783.65373
src: thumb/6a/f8/de2116a3a8408f8cf7a579ed0f0a-545886a3-6edfc5
width: 500
version: 1
9.1.4. video
Thevideo-handler processes all video/*, extracts some metadata and tries to extract some frames as still pictures.
See Cookbook: Videos for more details.
9.1.5. audio
audio-handler processes all audio/*, extracts metadata, e.g. from MP3 content the title, album etc, and if possible creates a waveform picture for preview.
% mls -l fables_01_01_aesop_64kb.mp3
fables_01_01_aesop_64kb.mp3
uid: ee93d0b3271c7743b6e5e230c7bf4b1c830ca01fede07b627ddc929d1ef1060e
size: 373,155 bytes
mime: audio/mpeg
otime: 2014/09/17 10:22:20.302 (1day 20hrs 8mins 38secs ago)
ctime: 2014/09/17 10:22:20.302 (1day 20hrs 8mins 38secs ago)
mtime: 2014/09/17 10:22:20.345 (1day 20hrs 8mins 38secs ago)
utime: 2014/09/17 10:22:20.345 (1day 20hrs 8mins 38secs ago)
atime: 2014/09/17 10:22:20.345 (1day 20hrs 8mins 38secs ago)
hash: f19f86d2658f39c64187492903c0100a846fa63a72131574f20f49257959c9da
audio:
album: Aesop's Fables Volume 1
artist: Aesop
duration: 46secs 600ms 0us
title: The Fox and The Grapes
thumb:
height: 256 px
src: thumb/ee/93/d0b3271c7743b6e5e230c7bf4b1c830ca01fede07b627ddc929d1ef1060e
width: 384 px
version: 1
See Cookbook: Audios for more details.
9.1.6. text
Thetext-handler tries to find strings, tries to determine the encoding.
MIME: text/*, application/octet-stream
- indexes all words found in the file in the full text index (fts)
- guesses
text.encodingbased on first 512 bytes found (ascii,utf- orbinary`) - extracts an excerpt to
text.excerpt
See Cookbook: Texts for more details.
9.1.7. html
Thehtml-handler primarly extracts metadata as found in the HTML, and makes it available in text.html.* and text.html.meta.*
MIME: text/html
- indexes actual content (without tags) in full text index
- makes metatags available
- makes links available (<a href="link">content</a>)
- inherents title from
<title> - inherents charset information into
text.encoding - extracts an excerpt to
text.excerpt
See Cookbook: Texts: HTML for more details.
9.1.8. pdf
Thepdf-handler extracts some PDF metadata and makes it available in text.pdf.* and guesses the title too.
MIME: application/pdf
- indexes actual text content into full text index
- extracts metadata into
text.pdf.* - extracts an excerpt to
text.excerpt
image-handler
See Cookbook: Texts: PDF for more details.
9.1.9. odf
Theodf-handler deals with all the Open Document Formats (ODF) such as:
- ODT: Open Document Text Document
- ODG: Open Document Graphics
- ODP: Open Document Presentation
- ODS: Open Document Spreadsheet
application/zip (odf files actually are a bunch of files zipped)
- extracts text and index in full text index
- extracts thumbnail
- extracts an excerpt to
text.excerpt - extract metadata into
odf.*- parses date/time if necessary (
dc_dateormeta_creation-date) and copied totext.ctime&text.mtime - guesses author (
text.author) and title of document (text.title->title) - inherents keywords and comments (
text.keywords&text.comments)
- parses date/time if necessary (
% mls -l Metadata.odt
...
odf:
office_meta: {
dc_creator: "Joe Sixpack"
dc_date: 2015-02-11T12:32:10.170720790
dc_description: "Brief description of what metadata is."
dc_subject: "Metadata explanation"
dc_title: Metadata
meta_creation-date: 2013-12-13T12:22:22.326000000
meta_document-statistic: {
meta_character-count: 1028
meta_image-count: 0
meta_non-whitespace-character-count: 877
meta_object-count: 0
meta_page-count: 1
meta_paragraph-count: 3
meta_table-count: 0
meta_word-count: 154
}
meta_editing-cycles: 7
meta_editing-duration: PT7M57S
meta_generator: "LibreOffice/4.2.7.2$Linux_X86_64 LibreOffice_project/420m0$Build-2"
meta_keyword: [ metadata, wikipedia ]
}
office_version: 1.2
xmlns_dc: http://purl.org/dc/elements/1.1/
xmlns_grddl: http://www.w3.org/2003/g/data-view#
xmlns_meta: urn:oasis:names:tc:opendocument:xmlns:meta:1.0
xmlns_office: urn:oasis:names:tc:opendocument:xmlns:office:1.0
xmlns_ooo: http://openoffice.org/2004/office
xmlns_xlink: http://www.w3.org/1999/xlink
parent: 0
text:
author: "Joe Sixpack"
comments: "Brief description of what metadata is."
ctime: 2013/12/13 12:22:22.000 (1yr 2months 8days 5hrs 12mins 52secs ago)
excerpt: "Metadata The term metadata refers to "data about data". The term is ambiguous, as it is used for two fundamentally different concepts (types). Structural metadata is about the design and specification of data structures and is more properly called "data about the containers of data"; descriptive metadata, on the other hand, is about individual instances of application data, the data content. Metadata are traditionally found in the card catalogs of libraries. As information has become inc"
keywords: [ metadata, wikipedia ]
language: en
lines: 1
mtime: 2015/02/11 12:32:10.000 (7days 5hrs 3mins 4secs ago)
title: Metadata
uniqueWords: 95
words: 164
thumb:
height: 256 px
mime: image/x-png
mtime: 2015/02/11 16:53:36.113 (7days 0hr 41mins 38secs ago)
src: thumb/96/db/db99a0671aa26d27fecf821caa4e-54db890f-6a6b1a
width: 181 px
9.1.10. epub
Theepub-handler extracts metadata, extract text content of the ebook into FTS, and uses cover image as thumbnail:
EPUBcontains the original metadata as parsed from entry point (html), mostlydc_*keystext.authortext.copyrighttext.descriptiontext.chapters, count of chapterstext.ctime/text.mtime/text.otimetext.publisher
% mls -l "The Man Who Cycled the World.epub"
The Man Who Cycled the World.epub
title: "The Man Who Cycled the World"
author: "Mark Beaumont"
copyright: "Copyright (c) 2011 by Mark Beaumont"
uid: 8f49aa57511ba291a56d46abaa169c50-57038d8f-e7624e
size: 3,229,546 bytes
mime: application/zip
otime: 2011/06/28 12:00:00.000 (4y 9mo 9d 2hr 8m 23s ago)
ctime: 2016/04/05 10:03:59.791 (4hr 4m 23s ago)
mtime: 2011/06/28 12:00:00.000 (4y 9mo 9d 2hr 8m 23s ago)
utime: 2016/04/05 10:04:00.124 (4hr 4m 23s ago)
atime: 2016/04/05 10:04:00.000 (4hr 4m 23s ago)
mode: rw-rw-r--
hash: 1d9e6827def255495bba06c7e00596350abf213f3f1d18e0c1d5ee7193bd4c78
EPUB:
dc_creator: "Mark Beaumont"
dc_date: 2011-06-28
dc_identifier: 978-0-307-71666-8
dc_language: en-US
dc_publisher: Crown/Archetype
dc_rights: "Copyright (c) 2011 by Mark Beaumont"
dc_title: "The Man Who Cycled the World"
description: "<p><b>The remarkable true story of one man's quest to break the record for cycling around the world</b><br><br
>On the 15th of February 2008, Mark Beaumont had pedaled through the Arc de Triomphe in Paris--194 days and 17 hours after setting o
ff in an attempt to circumnavigate the world. His journey had taken him, alone and unsupported, through 18,297 miles, 4 continents,
and numerous countries. From broken wheels and unforeseen obstacles in Europe, to stifling Middle Eastern deserts and deadly Austral
ian spiders, to the highways and backroads of America, he'd seen the best and worst that the world had to offer. <br><br>He had also
smashed the Guinness World Record by an astonishing 81 days. This is the story of how he did it.<br>Told with honesty, humor, and w
isdom, <i>The Man Who Cycled the World</i> is at once an unforgettable adventure, an insightful travel narrative, and an impassioned
paean to the joys of the open road.<br><br><i>From the Trade Paperback edition.</i>"
meta: {
cover: {
content: cover-image
}
epubcheckdate: {
content: 2011-06-20
}
epubcheckversion: {
content: 1.2
}
}
xmlns_dc: http://purl.org/dc/elements/1.1/
xmlns_opf: http://www.idpf.org/2007/opf
description: "The remarkable true story of one man's quest to break the record for cycling around the world On the 15th of February
2008, Mark Beaumont had pedaled through the Arc de Triomphe in Paris--194 days and 17 hours after setting off in an attempt to circ
umnavigate the world. His journey had taken him, alone and unsupported, through 18,297 miles, 4 continents, and numerous countries.
From broken wheels and unforeseen obstacles in Europe, to stifling Middle Eastern deserts and deadly Australian spiders, to the high
ways and backroads of America, he'd seen the best and worst that the world had to offer. He had also smashed the Guinness World Reco
rd by an astonishing 81 days. This is the story of how he did it. Told with honesty, humor, and wisdom, The Man Who Cycled the World
is at once an unforgettable adventure, an insightful travel narrative, and an impassioned paean to the joys of the open road. From
the Trade Paperback edition."
text:
author: "Mark Beaumont"
chapters: 50
copyright: "Copyright (c) 2011 by Mark Beaumont"
ctime: 2011/06/28 12:00:00.000 (4y 9mo 9d 2hr 8m 23s ago)
description: "The remarkable true story of one man's quest to break the record for cycling around the world On the 15th of
February 2008, Mark Beaumont had pedaled through the Arc de Triomphe in Paris--194 days and 17 hours after setting off in an attempt
to circumnavigate the world. His journey had taken him, alone and unsupported, through 18,297 miles, 4 continents, and numerous cou
ntries. From broken wheels and unforeseen obstacles in Europe, to stifling Middle Eastern deserts and deadly Australian spiders, to
the highways and backroads of America, he'd seen the best and worst that the world had to offer. He had also smashed the Guinness Wo
rld Record by an astonishing 81 days. This is the story of how he did it. Told with honesty, humor, and wisdom, The Man Who Cycled t
he World is at once an unforgettable adventure, an insightful travel narrative, and an impassioned paean to the joys of the open roa
d. From the Trade Paperback edition."
entities: [ (26 entries, hidden due verbosity) ]
excerpt: "The Man Who Cycled the World The Man Who Cycled the World The Man Who Cycled the World The Man Who Cycled the Worl
d The Man Who Cycled the World The Man Who Cycled the World The Man Who Cycled the World The Man Who Cycled the World Acknowledgment
sFrom a secret ambition, nurtured through university, the world cycle grew arms and legs to launch my career in the adventure world,
which I am now able to continue. It is one thing being good at what you plan to do, but it is quite another to find the emotional, to circumnavigate the world. His journey had taken him, alone and unsupported, through 18,297 miles, 4 continents, and numerous cou
ntries. From broken wheels and unforeseen obstacles in Europe, to stifling Middle Eastern deserts and deadly Australian spiders, to
the highways and backroads of America, he'd seen the best and worst that the world had to offer. He had also smashed the Guinness Wo
rld Record by an astonishing 81 days. This is the story of how he did it. Told with honesty, humor, and wisdom, The Man Who Cycled t
he World is at once an unforgettable adventure, an insightful travel narrative, and an impassioned paean to the joys of the open roa
d. From the Trade Paperback edition."
entities: [ (26 entries, hidden due verbosity) ]
excerpt: "The Man Who Cycled the World The Man Who Cycled the World The Man Who Cycled the World The Man Who Cycled the Worl
d The Man Who Cycled the World The Man Who Cycled the World The Man Who Cycled the World The Man Who Cycled the World Acknowledgment
sFrom a secret ambition, nurtured through university, the world cycle grew arms and legs to launch my career in the adventure world,
which I am now able to continue. It is one thing being good at what you plan to do, but it is quite another to find the emotional,
fi"
language: en
lines: 1
mtime: 2011/06/28 12:00:00.000 (4y 9mo 9d 2hr 8m 23s ago)
otime: 2011/06/28 12:00:00.000 (4y 9mo 9d 2hr 8m 23s ago)
publisher: Crown/Archetype
title: "The Man Who Cycled the World"
topics: [ (17 entries, hidden due verbosity) ]
uniqueWords: 10,179
verbosity: 14.4125159642401
words: 146,705
...
9.1.11. msword
Themsword-handler extracts metadata of Microsoft Word Documents into text.msword.*, and indexes the text body into FTS.
% mls -l UF-ENG-001World-2009-0.22.SRT.doc
...
text: {
language: en
lines: 105,644
msword: {
Company: "Hewlett-Packard Company"
Created: 2013-12-20T17:11:00Z
Creator: gremlin
EditingDuration: 2009-04-22T19:26:48Z
Generator: "Microsoft Office Word"
LastModified: 2013-12-20T17:11:00Z
LastSavedBy: gremlin
LinksDirty: FALSE
NumberOfCharacters: 5838585
NumberOfLines: 48654
NumberOfPages: 706
NumberOfParagraphs: 13698
NumberOfWords: 1024313
Revision: 2
Scale: FALSE
SecurityLevel: 0
Template: Normal.dotm
Title: "The Urantia Book"
Unknown1: 6849200
Unknown3: FALSE
Unknown6: FALSE
Unknown7: 786432
msoleCodepage: 1252
}
...
9.1.12. location
Thelocation-handler takes care of the Geonames database, used to assist lookup places in regards of GPS coordinates.
9.1.13. unarchive
Theunarchive-handler deals with archives of multiple kinds:
- tar, tar.gz, tar.bz2
- zip
- rar
- xz
- 7z
9.1.14. barcode

barcode-handler takes an image (image/jpeg) and searches for barcodes (1D and 2D QR) and lists them in the metadata.
For now you have to manually invoke this handler:
% mtrigger barcode scan *.jpg
Remember, most handlers are executed with triggers asynchronously, so give it a few moments until you check again with mfind barcodes: for example.
% mfind -l barcodes: | more
20140730_112500.jpg
uid: 04b90810a5ccdfb4d0eb1677b36ed0b7af0f591f2f83509053f410e0c74bf15b
size: 2,771,122 bytes
mime: image/jpeg
otime: 2014/07/30 11:25:00.000 (1month 19days 2hrs 22mins 48secs ago)
ctime: 2014/09/18 13:46:03.379 (1min 45secs ago)
mtime: 2014/07/30 11:25:00.000 (1month 19days 2hrs 22mins 48secs ago)
utime: 2014/09/18 13:46:03.524 (1min 45secs ago)
atime: 2014/09/18 13:46:03.524 (1min 45secs ago)
hash: 0e9fcf4d5136f042711c031415cc86a0b2062e072bf3cb32b0529bc5c1d5aaac
barcodes: [
code: 4007873916717 type: EAN-13,
code: 4024506266575 type: EAN-13,
code: 4024506267428 type: EAN-13 ]
image:
EXIF:
...
conf/metafs.conf, enable "update" line:
"barcode": {
"update": { "mime": "image/jpeg", "priority": 13, "nice": 20 },
"scan": { "mime": "image/jpeg", "priority": 13, "nice": 20 }
},
Note: current barcode-handler is very memory intensive - be aware of it.
9.2. Writing Handlers
Writing custom handlers is one of the features of , please consult the Programming Guide.
10. Configuration
The main configuration is defined viaconf/metafs.conf and resides for system-wide use in /var/lib/metafs/ by default, which looks a bit like this - glance over it to get an impression what can be changed:
# -- sample conf file for metafs in JSON, '#' indicates comment
{
"verbose": 0, # 0 = none, 1 = little, 2 = higher, 3 = max
"backend": "mongo",
"mongo": { # mongodb specific settings
"type": "shared", # default "shared", or "dedicated" (running separate mongod for metafs)
"host": "localhost",
"port": 27017 # if type = "dedicated", choose new port (e.g. 21020)
},
# "root": "/var/lib/metafs",
# -- encryption isn't available yet
# "encryption": {
# "cipher": "aes",
# "status": "on", # default: off
# },
"trash": {
"status": "on", # default off, "on" = put deleted items into trash (possibility to undelete)
"size": "1000000000" # once trash reaches 1000MB, oldest items will be purged
},
"expose": {
# "dotmjson": "on", # expose metadata as .filename.mjson
"node": "on" # expode nodes as filename+
},
# -- access policy of reserved / mandatory keys, ro = read-only, rw = read/write
"access": {
"_id": "ro",
"uid": "ro",
"size": "ro",
"ctime": "ro",
"mtime": "rw", # permit mmeta to alter modification time
"atime": "ro",
"utime": "ro",
"otime": "rw", # permit mmeta to alter origin time
"hash": "ro",
"type": "rw",
"name": "rw",
"tags": "rw",
"parent": "ro",
"mode": "rw"
},
"getdir": {
"typeMap": {
"folder": "",
"node": "+"
},
"typeFunction": {
"folder": "folderOnly",
},
},
"types": { # types: "number", "decimal", "string", "date", "time", "binary", "octal", "hexadecimal", "umode"
"size": "number",
"name": "string",
"ctime": "date",
"mtime": "date",
"atime": "date",
"utime": "date",
"otime": "date",
"mode": "umode", # UNIX mode (e.g. "-rwxr-xr-x")
},
"units": {
"size": "bytes"
},
"queue": {
"maxPriority": 32, # max priority, priority 1 (highest), 32 (lowest)
"nice": 5, # set default nice for all triggers
"order": 1, # order of execution (1: oldest first / FIFO, -1: newest first / LIFO)
"limits": { # limits for all handlers & triggers (be careful, some handlers like video -> semantics takes minutes)
# "vmem": 4000,
# "rmem": 2000,
# "aspace": 4000,
# "cpu": 120,
}
},
# -- handlers:
"handlers": {
# -- Note: the order matters, set via "priority": e.g. "version"-handler requires proper metadata,
# means the "hash"-handler has to be calculated before
# "mime": { # mime is determined in the core, commented out for now
# "priority": 1, # executed 1st
# "triggers": {
# "update": { "exec": "sync" }, # sync executed, right away
# }
# },
"hash": {
"priority": 2, # executed 2nd
"triggers": {
"update": { "exec": "sync" }, # sync executed, right away
"fsck": { }
}
},
"text": {
# "limits": { "cpu": ..., "rmem": ..., "vmem": ... }, # per handler limits
"triggers": {
# "something": { "limits": { "cpu": ... }, ... }, # per trigger limits
"update": { "mime": [ "text/*", "application/octet-stream" ], "priority": 3 },
"delete": { "mime": [ "text/*", "application/octet-stream" ], "priority": 3 },
"undelete": { "mime": [ "text/*", "application/octet-stream" ], "priority": 3 }
}
},
"html": {
"triggers": {
"update": { "mime": [ "text/html" ], "priority": 6 },
"delete": { "mime": [ "text/html" ], "priority": 6 },
"undelete": { "mime": [ "text/html" ], "priority": 6 }
}
},
"image": {
"triggers": {
"init": { },
"update": { "mime": [ "image/*", "application/pdf" ], "priority": 6, "nice": 10 },
"purge": { "mime": [ "image/*", "application/pdf" ], "priority": 6, "nice": 10 }
}
},
"video": {
"triggers": {
"update": {
"limits": { "cpu": -1 }, # ensure unlimited for semantics analysis
"mime": [ "application/ogg", "video/*" ], "priority": 6, "nice": 10
},
"delete": { "mime": [ "application/ogg", "video/*" ], "priority": 6, "nice": 10 },
"undelete": { "mime": [ "application/ogg", "video/*" ], "priority": 6, "nice": 10 },
"purge": { "mime": [ "application/ogg", "video/*" ], "priority": 6, "nice": 10 },
"explode": { "mime": [ "application/ogg", "video/*" ], "priority": 22, "nice": 20 }
}
},
"audio": {
"triggers": {
"update": { "mime": "audio/*", "priority": 6 },
"delete": { "mime": "audio/*", "priority": 6 },
"undelete": { "mime": "audio/*", "priority": 6 },
"purge": { "mime": "audio/*", "priority": 6 }
}
},
"fts": {
"triggers": {
"init": { },
#"update": { "mime": [ "text/*", "application/octet-stream", "application/pdf" ], "priority": 10, "nice": 10 },
#"delete": { "mime": [ "text/*", "application/octet-stream", "application/pdf" ], "priority": 10, "nice": 10 },
"fsck": { },
"fsinfo": { }
}
},
"pdf": {
"triggers": {
"update": { "mime": "application/pdf", "priority": 10 },
"delete": { "mime": "application/pdf", "priority": 10 },
"undelete": { "mime": "application/pdf", "priority": 10 }
}
},
"odf": {
"triggers": {
"update": { "mime": "application/zip", "priority": 10 },
"delete": { "mime": "application/zip", "priority": 10 },
"undelete": { "mime": "application/zip", "priority": 10 }
}
},
"location": {
"triggers": {
"init": { }, # "exec": "sync" },
# "1
update": { "mime": "image/jpeg", "priority": 12 },
"fsinfo": { }
}
},
"barcode": {
"triggers": {
# "update": { "mime": "image/jpeg", "priority": 13, "nice": 20 }
"scan": { "mime": "image/jpeg", "priority": 13, "nice": 20 }
}
},
# -- miscellaneous triggers (non item related)
# "webstat": {
# "triggers": {
# "init": { }
# }
# },
# "webapi": { # -- no longer exists since 0.038, due support of multi-volumes, now is metaapi
# "triggers": {
# "init": { }
# }
# },
"snapshot": {
"triggers": {
"fsck": { },
"fsinfo": { },
"mksnap": { } # we call it via metabusy trigger mksnap
}
},
# "rss": {
# "triggers": {
# "init": { }
# }
# }
}
}
10.1. Per Volume Configuration
Allconf/* can also reside in the volume specific directory, e.g. for volume alpha it is /var/lib/metafs/volumes/alpha/conf and overrides the system-wide configuration.
volumes/
alpha/
conf/
metafs.conf
metabusy.conf
...
Best way is, copy the /var/lib/metafs/conf/ configuration files to your volume specific conf/, and alter the settings volume specific.
Note: Since is still very experimental, the entire conf/* files are subject of drastic changes - so when you maintain volume specific configuration make sure you keep up with the current configuration form.
In other words, keep looking into /var/lib/metafs/conf/* to see what has changed, addded or even removed and adapt those to your volume specific configuration files.
11. Backends
is implemented by various components:
11.1. UNIX Filesystem
Once is installed system-wide, you find the core at/var/lib/metafs/:
conf/metafs.conf: configuration file formetafs- and other .conf files specific to triggers
handlers/: folder with handlers for different triggers/events and mime-typeslib/: files which server as base library (e.g. extension to mime-type mapping, or raw geonames database)volumes/:- {volume} (e.g. "alpha")
files/actual content of the files/itemsthumb/thumbnails of files/itemsmongo/: oncemetabusy backupis used, there the MongoDB / TokuMX dump is saved toelastic/: oncemetabusy backupis used, there the Elasticsearch index dump is saved tolog/: each volume has its own log filesaccess.log, main log fileerror.log, error log file (watch this!)triggers.log, all trigger related stuff
- {volume} (e.g. "alpha")
/usr/local/bin:
metafs: main program creating a layer of on top of the UNIX file system, e.g.metafs alpha Alpha/metabusy: 'busybox'-like perl-script providingmls, mfind, mtag, mcpetc through symbolical links
/sbin:
mount.metafs=>/usr/local/bin/metafsumount.metafs=>/usr/local/bin/metafsmount.fuse.metafs=>/usr/local/bin/metafs
metafs itself.
Various metadata backends can be used:
| Backend | NoSQL Maturity | Memory Usage | MetaFS Functionality | Availability | |
| MongoDB 3.0.x | mongo | mature | high | full | open source |
| TokuMX 2.0.x | mongo | experimental | high | full | open source |
| PostgreSQL 9.4 | pg | experimental | low | limited | open source |
| MetaFS::IndexDB 0.1.x | ix | experimental | low | full | not available yet |
11.2. IndexDB
A volume is mapped tometafs_{volume}, like metafs_alpha:
metafs_{volume}.items: metadata of the filesmetafs_{volume}.trash: metadata of the files in the trash binmetafs_{volume}.triggers_{i}: is the trigger queue, triggers executed asqueue(default), whereas i is 1..32
11.3. MongoDB / TokuMX
A volume is mapped tometafs_{volume}, like metafs_alpha:
metafs_{volume}.items: metadata of the filesmetafs_{volume}.trash: metadata of the files in the trash binmetafs_{volume}.triggers_{i}: is the trigger queue, triggers executed asqueue(default)metafs_{volume}.fts: full text search index (word -> file(s), file -> word(s)) iffts.engine = 'native'metafs_{volume}.journal:journalpopulates it for its own purpose
geonames resides shared or locally, location-handler with init-trigger creates this village/city -> lat/long mapping, required for supporting mfind location:city=Somewhere
geonames: shared ormetafs_{volume}.geonames: dedicated
conf/location.conf.
11.3.1. Shared & Dedicated MongoDB / TokuMX
By default uses the same MongoDB / TokuMX to store different volumes, you can change this atconf/metafs.conf:
"mongo": { # mongodb specific settings
"type": "shared", # default "shared", or "dedicated" (running separate mongod for metafs)
"host": "localhost",
"port": 27017 # if type = "dedicated", choose new port (e.g. 21020)
},
11.3.3. MongoDB vs TokuMX
By default (for now) MongoDB is used as backend metadata database, but TokuMX (2.0.0 or later) is recommended:
| MongoDB 2.4/2.6 | TokuMX 2.0.0 | |
| Insertion Speed | 1x | 10-20x[1] |
| Query Speed | 1x | 10-20x[2] |
| DB File Size | 100% | 10-20% |
At a later time TokuMX might become default for MetaFS. Other NoSQL databases are constantly reviewed and action has been taken to abstract the metadata handling so flexibility is gained to support other NoSQL databases as well.
11.4. TokuMX Installation
Best download the binary distribution, extract it and startmongod manually, or remove mongodb package first (apt-get remove mongodb) and install the new binaries to /usr/bin:
% cd tokumx-2.0.0*
% sudo cp bin/mongo* /usr/bin/
TokuMX requires tranparent hugepage disabled, run the following line as root and add it to /etc/rc.local:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
You can also run multiple different databases at different ports, and add dedicated metafs.conf per volume to use those different databases to compare and benchmark backends.
11.5. PostgreSQL
An experimental PostgreSQL backend is implemented, minimum requirement is PostgreSQL 9.4 to take advantage of the newly available NoSQL features. This backend is not optimized and tends to be slow compared to IndexDB or MongoDB, but is more reliable.
11.6. Elasticsearch
Iffts.engine is set to "elastic" in metafs.conf, the Elasticsearch.org is used for full text search (FTS), metafs_{volume} is the name of the index, like metafs_alpha.
Needless to say, don't tamper with Elasticsearch index manually as it will create an inconsistant full text search index. At a later time other full text search (FTS) backends might be added.
12. Updates
Significant updates of this document:- 2016/10/24: 0.7.5:
handlerssection ofmetafs.confupdated (new sub structuretriggers) (rkm) - 2016/04/05: 0.6.2:
epubdocumented (rkm) - 2015/09/12: 0.5.1: taking out programming/development part and moved it into Programming Guide
- 2015/09/04: 0.5.0: updated technical overiew illustration
- 2015/02/18: 0.4.4: more details on handlers:
text,pdf,odf(rkm) - 2015/02/14: 0.4.3:
marccommand documented (rkm) - 2015/02/10: 0.4.2:
mmetasupporting smart values (rkm) - 2015/01/18: 0.3.20: linking Cookbook where
image-,video- andaudio-handler are explained in more details (rkm) - 2014/10/03: 0.3.13 (rkm)
- 2013/12/15: first version with basics (rkm)
- rkm: René K. Müller
13. Word Index
- Absolute dates: [Absolute Dates]
- Backup a volume: [backup]
- delete files: [mrm]
- Equality: [Equality, Inequality or Not Equal]
- inequalities: [Equality, Inequality or Not Equal]
- information of the filesystem: [mfsinfo]
- memory sizes: [Memory & Storage Size]
- node with data: [Node]
- not equal: [Equality, Inequality or Not Equal]
- range: [Smart Expressions / Ranges]
- Regular expressions: [Regular Expression]
- Relative timing: [Relative Timing]
- Restore a volume: [restore]
- Smart values: [Smart Values]
- storage sizes: [Memory & Storage Size]
- times: [Time]
- type of the item: [Item Types]
- volume: [Fundamentals]
 MetaFS.org - the metadata file system - Creative Commons CC 3.0 BY SA 2013-2019
MetaFS.org - the metadata file system - Creative Commons CC 3.0 BY SA 2013-2019